Table of Contents
LinkedIn Jobs Recommendation Systems
In this tutorial, you will learn about LinkedIn Jobs recommendation systems.

LinkedIn has made it easier for professionals to connect and build their network, look for new job opportunities, get professional advice from others in the same field, and build connections to help them advance in their careers.
LinkedIn has also become a popular platform for recruiters to find new talent. It allows recruiters to search for candidates based on their skills, experience, and other criteria. This has made it easier for companies to find candidates for their job openings. In addition, LinkedIn provides a great platform to recruit top-notch talent, especially for startups, which don’t have enough visibility compared to multinational corporations.
Apart from making job and talent hunting easier, LinkedIn now offers a variety of resources for professionals to upgrade their skills and advance their careers. This includes online courses, certifications, and webinars that are up-to-date with industry standards. Furthermore, it helps professionals build their brands by helping them establish themselves as thought leaders in their fields and making it easier for others to find them online.
Behind the scenes are LinkedIn’s amazing recommendation systems (Figure 1) that provide professionals or recruiters with a personalized feed, jobs they are interested in, connections and courses that can help them advance their careers, the best candidates for their job description (for recruiters and companies), etc.

In this lesson, we will cover several aspects of LinkedIn recommendations (e.g., feed recommendations, talent recommendations, course recommendations) and how they work behind the scenes.
This lesson is the last in a 3-part series on Deep Dive into Popular Recommendation Engines 101:
- Fundamentals of Recommendation Systems
- Netflix Movies and Series Recommendation Systems
- LinkedIn Jobs Recommendation Systems (this tutorial)
To learn how LinkedIn recommendations work, just keep reading.
LinkedIn Jobs Recommendation Systems
Most of the LinkedIn recommendations are powered by artificial intelligence (AI) in some way or another. For example, LinkedIn uses AI in ways its members experience daily, like recommending the right job opportunities, encouraging them to connect with someone (“People You May Know” feature), providing relevant content on their feed, providing course suggestions to upgrade their skills, suggesting recruiters with the best talent for their job openings, etc.
In this lesson, we will discuss LinkedIn’s three major recommendation systems: Feed, recruiter search, and course recommendations.
Feed Recommendations
LinkedIn Feed
LinkedIn feed (Figure 2) is a sorted list of updates displayed to its members when they log in. It comprises a heterogeneous inventory of updates (e.g., articles shared by connected members, job recommendations, news recommendations, people you may know recommendations, stories mentioning companies the member follows, etc.).

The feed aims to keep LinkedIn members updated and informed in their professional world. Feed recommendation estimates the utility of an update for a particular member. It is similar to a recommendation system that suggests movies but with a few twists.
Most members interact heavily with the feed by scrolling down. Therefore, displaying where the member will likely engage in interactive sessions rather than the latest feed is very important. Furthermore, the feedback collected is based on members’ implicit actions (e.g., time spent on a feed, clicks, comments, likes, etc.) rather than explicit actions (e.g., rating the feed on a scale of 1-5 as done for movies).
Incorporating LinkedIn’s social graph in recommendations is another important aspect, as members often find updates shared, liked, or commented on by their connections relevant. Moreover, members are incentivized to update their profiles as it attracts other people and companies. This allows LinkedIn’s feed recommendation system to access high-quality data about members’ interests, skills, and backgrounds.
First Pass Rankers
The LinkedIn feed recommendation system (Figure 3) comprises two engines: First Pass Rankers (FPRs) and Second Pass Rankers (SPRs). First Pass Rankers are responsible for separately ranking items according to user relevance for each inventory (i.e., articles, news, jobs, connections, etc.). Top-k items from each inventory (ranked by FPRs) are then passed through Second Pass Rankers (SPRs), which combine all these outputs from FPRs to create a single personalized ranked list. After SPR, the ranked list is passed to a re-ranker that modifies the output of SPR and creates the final list of feeds to be displayed on the homepage.

Figure 3 shows the general architecture of the feed recommendation system. First, multiple FPRs (in the left part of the figure) feed the top-k items from different inventories into SPRs that combine all these ranked lists into a single ranked list which is sent to the front.
Next, Figure 4 focuses on the FPRs, which pass top-k items from different inventories to the feed mixer (second pass ranker + re-ranker). One of the important FPRs is “activities from your network,” which includes shares from people and companies that members follow. This source comprises 50% of updates shown in the LinkedIn feed.
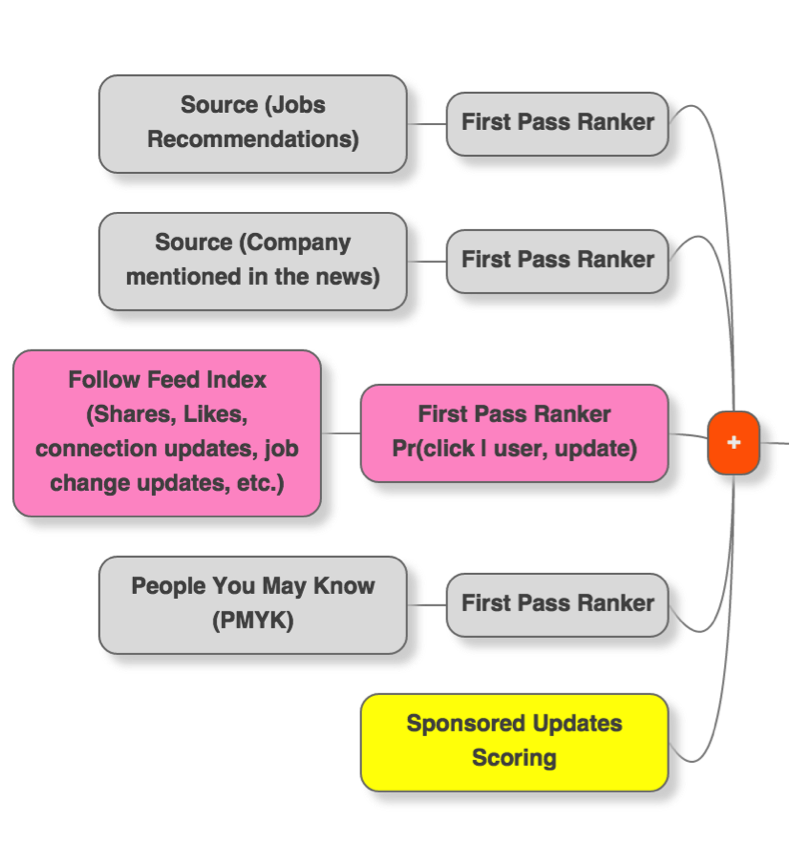
The reason for having multiple FPRs is that different teams having different domain expertise can own different FPRs allowing them to work efficiently. Furthermore, having a second pass maker will enable LinkedIn to use additional features and complex ranking rules, which otherwise would be costly if done for each FPR.
Second Pass Ranker
The core of SPR (Figure 5) is a logistic regression model that takes the user profile (e.g., skills, interests, background), the feed candidate, and its FPR score as inputs and computes the probability that the member will interact with that update (e.g., like, comment, share, etc.).
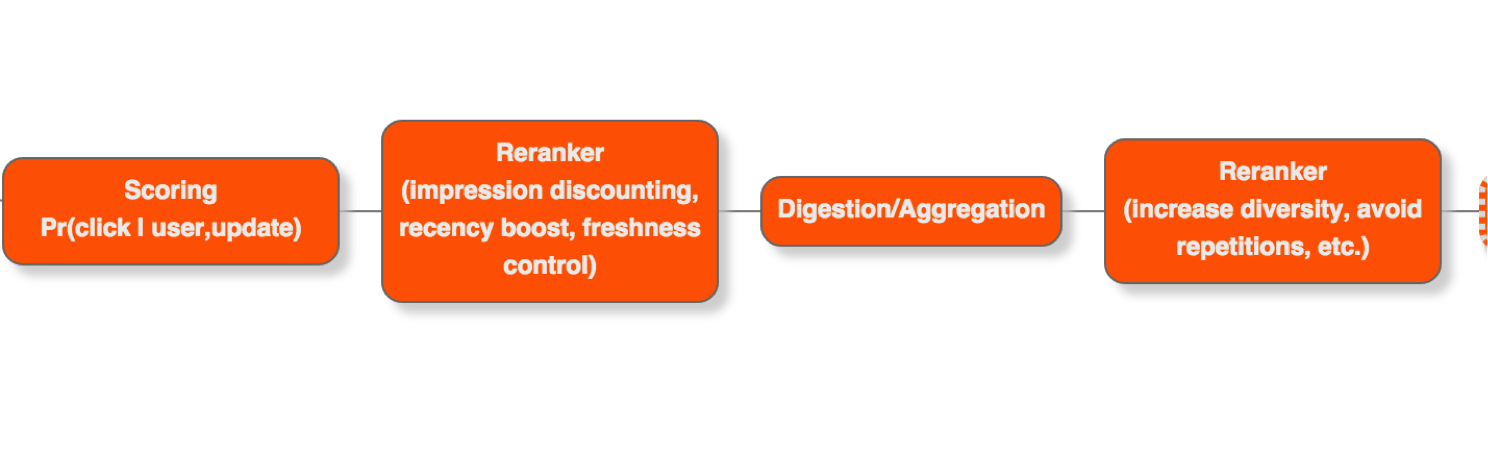
LinkedIn uses several metrics to measure the engagement level of a member with a feed item (e.g., number of clicks, likes, comments, follows, connects, re-shares, and whether the user scrolled down to view at least 10 updates, etc.). These metrics can then calculate the overall interaction per user, known as Click Through Rate (CTR), which is the probability that a member will click/like/share/comment on a feed item shown to them.
Metrics that capture immediate reaction to the feed are called upstream metrics (e.g., interactions or CTR). In contrast, downstream metrics capture the delayed reaction of the user to the feed (e.g., engaged feed sessions). In general, it is much easier to predict and optimize upstream metrics than downstream metrics.
The logistic regression model estimates the CTR given user features and item features. Let  be a binary variable to represent the interaction between user
be a binary variable to represent the interaction between user  and update
and update  (
( if there is an iteration,
if there is an iteration,  otherwise). Assuming
otherwise). Assuming  be the features corresponding to user and item , the logistic regression model can be written as:
be the features corresponding to user and item , the logistic regression model can be written as:
![\log\left(\displaystyle\frac{P(y_{it}=1 | \text{user}=i, \text{update}=t)}{1-P(y_{it}=1 | \text{user}=i, \text{update}=t)}\right) = \sum_j \beta_j [X_{it}]_j,](https://b2633864.smushcdn.com/2633864/wp-content/latex/8d7/8d77ac190d81503ea2d6d5a0fc719842-ffffff-000000-0.png?lossy=2&strip=1&webp=1 "\log\left(\displaystyle\frac{P(y_{it}=1 | \text{user}=i, \text{update}=t)}{1-P(y_{it}=1 | \text{user}=i, \text{update}=t)}\right) = \sum_j \beta_j [X_{it}]_j,")
where  are the model parameters. The model is trained over fixed data collected over some time. For some
are the model parameters. The model is trained over fixed data collected over some time. For some  updates shown to a member, the ones where the member interacted are considered as positives (
updates shown to a member, the ones where the member interacted are considered as positives ( ), and others are considered as negatives (
), and others are considered as negatives ( ).
).
Evaluation
Offline evaluation is important before deploying the model in an online setting. LinkedIn uses two metrics for offline evaluation. The first one is the O/E ratio which calculates the ratio of observed (predicted by the logistic regression model) and the expected probabilities (ground truth). If O/E is less than , the CTR model overestimates pCTR probabilities. If it is greater than , the CTR model underestimates pCTR probabilities.
The second metric is “Replay,” which runs the trained logistic regression model on random historical data and records when the new model recommends updates that the user interacted with.
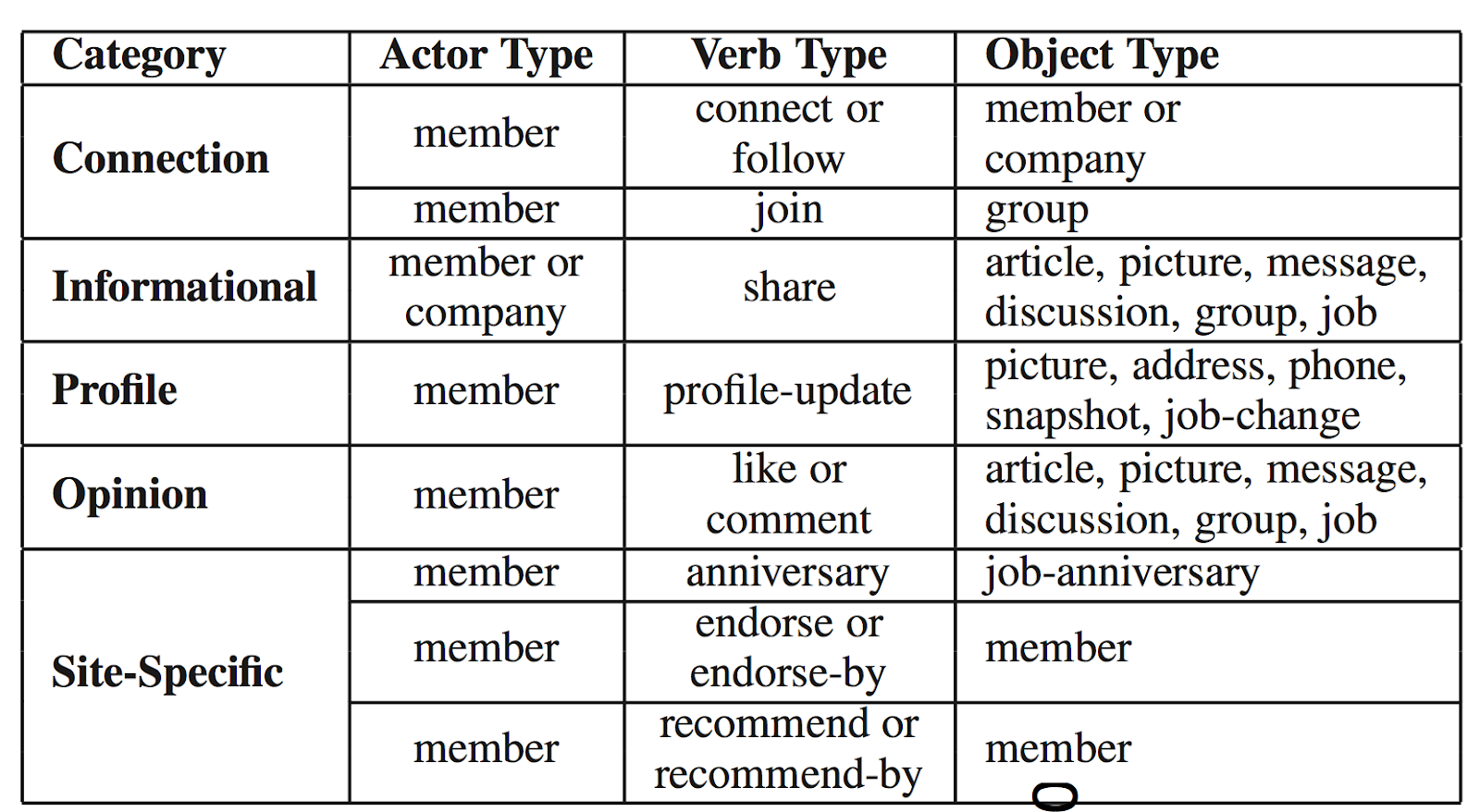
Feature Representation
Each feed activity (e.g., connection, like, share, update, etc.) is represented as a triplet (actor  , verb
, verb  , and object
, and object  ). So, for example, a member (actor) shared (verb) an update (object), a member (actor) updated (verb) his profile (object), etc. Table 1 shows the taxonomy of different feed activity triplets.
). So, for example, a member (actor) shared (verb) an update (object), a member (actor) updated (verb) his profile (object), etc. Table 1 shows the taxonomy of different feed activity triplets.
Let’s understand it more clearly by taking an example of activity about a job opening (for a Java developer) shared by Microsoft. Here actor is company Microsoft, verb is sharing of jobs, and object is the job description for Java developers.
Now, for a user and the activity (job posting from Microsoft), the feature used as input for the logistic regression model comprises the following features:
- User-only feature,
 , represents user profile, interests, skills, etc. (e.g., it will include features like if the user has expertise and experience in Java).
, represents user profile, interests, skills, etc. (e.g., it will include features like if the user has expertise and experience in Java). - Activity-only feature,
 , representing activity type (
, representing activity type ( ), actor type (), verb type () and creation time, FPR score, activity impression time, popularity, etc. (e.g., how many likes, comments, and shares the job posting received).
), actor type (), verb type () and creation time, FPR score, activity impression time, popularity, etc. (e.g., how many likes, comments, and shares the job posting received). - User-actor feature,
 , representing the interaction between user and actor (of update ) (e.g., whether the user follows Microsoft or not).
, representing the interaction between user and actor (of update ) (e.g., whether the user follows Microsoft or not). - User-activity feature,
 , captures the interaction between user and activity type (e.g., whether the user is looking for a job or has recently applied to any job).
, captures the interaction between user and activity type (e.g., whether the user is looking for a job or has recently applied to any job). - User-actor-activity feature,
 , captures the interaction between user, actor, and activity type (e.g., whether the user applied to a job posting by Microsoft in the past or recently).
, captures the interaction between user, actor, and activity type (e.g., whether the user applied to a job posting by Microsoft in the past or recently). - User-object feature,
 , capturing the interaction between user and object (e.g., whether the user is apt for the job posting).
, capturing the interaction between user and object (e.g., whether the user is apt for the job posting).
The feature is thus the concatenation of the above features, that is,
")
Recruiter Search Recommendations
Recruiter Talent Search and Recommendations is one of the major offerings by LinkedIn that contributes to around 65% of its annual revenue. It provides a marketplace to connect job seekers with job providers by enabling recruiters and companies to reach out to potential candidates for their job openings.
LinkedIn Talent Search and Recommendations
LinkedIn talent search recommendation system (Figure 6) provides a ranked list of potential candidates corresponding to a search query, which can be a text query, job description, etc. Given a search request (e.g., a software developer with a machine learning background ready to join in California), the candidates are ranked based on their experience with machine learning and expertise as a software developer, similarity of their work, living in California, and likelihood that they will respond to the job description.

For each result shown by the recommender system, the recruiter can then perform three actions:
- View the candidate’s profile
- Bookmark or save the candidate’s profile for further evaluation
- Send an InMail to the candidate
All these actions tell us that the recruiter finds the recommended candidate relevant for the job opening. However, suggesting a list of potential candidates that match the search query is inefficient if most are not interested in applying. Therefore, recommending talent to recruiters requires mutual interest between the recruiter and the candidate.
Therefore, a new feature, “InMail Accept,” is provided by LinkedIn to record the event when the candidate positively responds to the InMail request sent by the recruiter. Thus a candidate recommendation is said to be relevant when the recruiter sends an InMail and candidates positively respond to it.
The nature of search queries is usually complex, involving a combination of several structured fields (e.g., location, experience, etc.) and unstructured fields (e.g., free text). This makes the association between search queries and interested candidates complex and non-linear. Thus, LinkedIn leverages neural networks that can handle complex queries and capture the non-linear relationship between the query and the candidates.
Given a query  by a recruiter, we want to rank a list of LinkedIn members
by a recruiter, we want to rank a list of LinkedIn members  in order of decreasing relevance. In other words, we want to learn a function that assigns scores to each candidate based on their relevance to the query provided by the recruiter. To achieve this, LinkedIn knows the dense vector representations of question and member in a common subspace and then performs the final scoring afterward (e.g., cosine similarity between both vectors). There are two approaches to learning these representations: unsupervised and supervised.
in order of decreasing relevance. In other words, we want to learn a function that assigns scores to each candidate based on their relevance to the query provided by the recruiter. To achieve this, LinkedIn knows the dense vector representations of question and member in a common subspace and then performs the final scoring afterward (e.g., cosine similarity between both vectors). There are two approaches to learning these representations: unsupervised and supervised.
Unsupervised Approach
LinkedIn entities like skill, title, company, institution or school, and location (mentioned in query and member profile) are categorical and suffer from sparsity because of the large search space. This makes learning dense embeddings for these entities difficult to use traditional approaches like Word2vec. LinkedIn thus uses its economic graph to learn dense representations for these entities.
LinkedIn’s Economic Graph
LinkedIn’s Economic Graph is a digital representation of its economy based on data from over 500 million members, tens of thousands of standardized skills, employers and open jobs, and tens of thousands of educational institutions, along with the relationships between these entities. Vertices represent the network members, and edges represent the intensity of interaction (e.g., clicks, likes, shares, social actions, etc.) between the two members.
However, the economic graph is large and sparse, which results in intractable models and noisy embeddings. Hence, LinkedIn uses an entity graph, a sub-network of the economic graph representing only entities (skill, title, company) whose dense representations need to be learned.
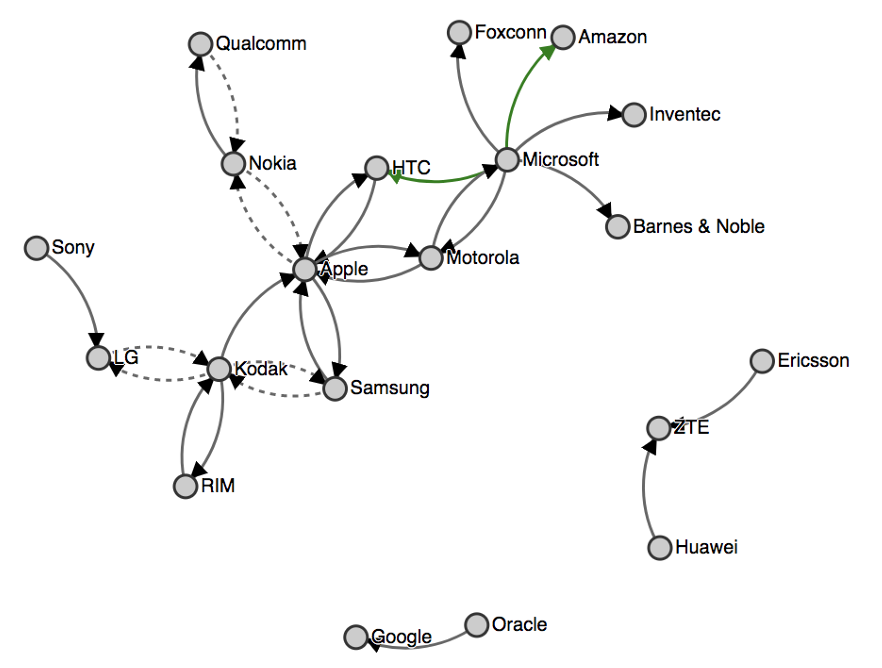
Figure 7 shows the entity graph representing companies. Each vertex represents a company, and an edge between two companies represents the LinkedIn members who have worked in both companies. In this example, the aim will be to calculate the dense representation of each company. Similar graphs can be constructed for other entity types (e.g., skills and schools).
First-Order Embeddings
First-order embeddings are generated based on the observation that vertices connected by an edge are similar. We define a joint probability distribution between vertices  and
and  connected by an edge of weight
connected by an edge of weight  as follows:
as follows:
 = \displaystyle\frac{\sigma(\langle u_i, u_j \rangle)}{\sum_{(v_m, v_n) \in E} \sigma(\langle u_m, u_n \rangle)},")
where  is the
is the  -dimensional embedding of vertex
-dimensional embedding of vertex  represents the dot product between two vectors, and
represents the dot product between two vectors, and  = \frac{1}{1+\exp(-x)}") is the sigmoid function. Set
is the sigmoid function. Set  consists of all edges of the entity graph. Next, we can define an empirical joint distribution between vertices and as follows:
consists of all edges of the entity graph. Next, we can define an empirical joint distribution between vertices and as follows:
 = \displaystyle\frac{w_{ij}}{\sum_{(v_m, v_n) \in E} w_{mn}}")
Finally, to learn embeddings  , we minimize the Kullback-Leibler (KL) divergence between
, we minimize the Kullback-Leibler (KL) divergence between  and
and  with respect to embeddings to preserve the first-order proximity:
with respect to embeddings to preserve the first-order proximity:
 \in E} \hat{p}_1(v_i, v_j) \log \displaystyle\frac{p_1(v_i, v_j) }{\hat{p}_1(v_i, v_j)}")
Second-Order Embeddings
Second-order embeddings are generated based on the observation that vertices having shared neighbors are similar. In this case, a vertex plays two roles: the vertex itself and the specific context for the other vertex. To represent this, we define the probability of a context vertex being generated by a vertex as follows:
 = \displaystyle\frac{\exp(\langle u^\prime_j, u_i \rangle)}{\sum_{k=1}^\vert V \vert \exp(\langle u^\prime_k, u_i \rangle)},")
where  represents the second-order embedding of vertex used when it is treated as a context, and
represents the second-order embedding of vertex used when it is treated as a context, and  is the total number of vertices in the entity graph.
is the total number of vertices in the entity graph.
The empirical probability can be written as follows:
 = \displaystyle\frac{w_{ij}}{\sum_{v_k: (v_i, v_k) \in E} w_{ik}}")
Finally, to learn embeddings and , we minimize the KL divergence between  and
and  with respect to embeddings to preserve the second-order proximity:
with respect to embeddings to preserve the second-order proximity:
 \in E} \hat{p}_2(v_j | v_i) \log \displaystyle\frac{p_2(v_j | v_i) }{\hat{p}_2(v_j | v_i)},")
where  is the degree of vertex representing its importance in the entity graph.
is the degree of vertex representing its importance in the entity graph.
Computing Relevance
After obtaining the first- and second-order embeddings and for a vertex , each entity (the company in our case) can now be represented as a single vector by concatenating its first- and second-order embeddings ![[u_i, u^\prime_i]](https://b2633864.smushcdn.com/2633864/wp-content/latex/364/364799c8ef1e1e42aeda83303a3cfb16-ffffff-000000-0.png?lossy=2&strip=1&webp=1 "[u_i, u^\prime_i]") .
.
Each query and member can be represented by a bag of companies (i.e., a query can contain multiple companies referenced in the search terms, and a member could have worked at multiple companies, which is manifested on the profile).
Thus, we can represent each query and member as a point on vector space with a simple pooling operation (max-pooling or mean-pooling) over the bag companies. A similarity function between two vector representations can be used as a feature ranking.
Supervised Approach
The supervised approach (Figure 8) to learning dense representations for query and member involves training three neural networks:
- A query network
") that embeds a given query to a fixed dimensional latent space.
that embeds a given query to a fixed dimensional latent space. - A member network
") embeds a given member to a fixed dimensional latent space.
embeds a given member to a fixed dimensional latent space. - A cross-network
") that takes a query and member embeddings and computes their relevance score.
that takes a query and member embeddings and computes their relevance score.
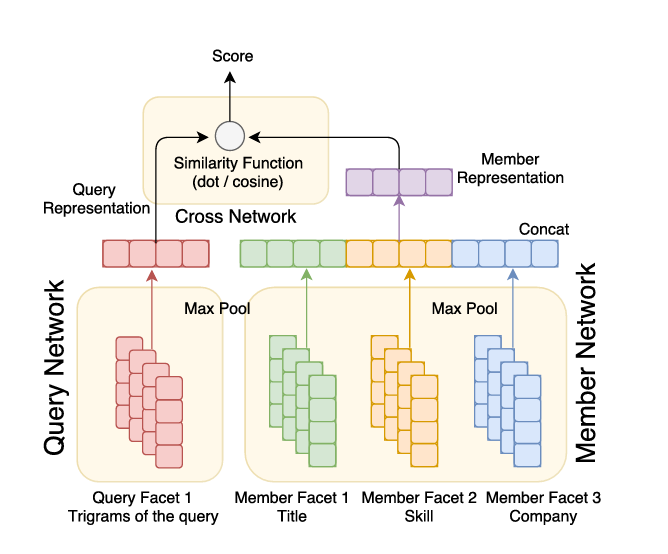
In other words, the predicted relevance score  for a query and member
for a query and member  is computed as:
is computed as:
, \phi_q(m))")
The cross-network can be a neural network of a similarity function such as cosine similarity.
These three models are trained over historically collected triplets ") , where
, where  is the query provided by the recruiter,
is the query provided by the recruiter,  is a member profile, and
is a member profile, and  is a binary label which is if the member was relevant to query and also accepted recruiter InMail request and
is a binary label which is if the member was relevant to query and also accepted recruiter InMail request and  otherwise (either candidate is not relevant to the query or s/he didn’t accept the InMail).
otherwise (either candidate is not relevant to the query or s/he didn’t accept the InMail).
Course Recommendations
LinkedIn Learning
LinkedIn Learning (Figure 9) is a platform that allows members to develop relevant skills through courses to advance their professional careers. Over the last few years, LinkedIn has developed a course recommendation system that recommends relevant courses to its members based on their interests and learning aspirations.
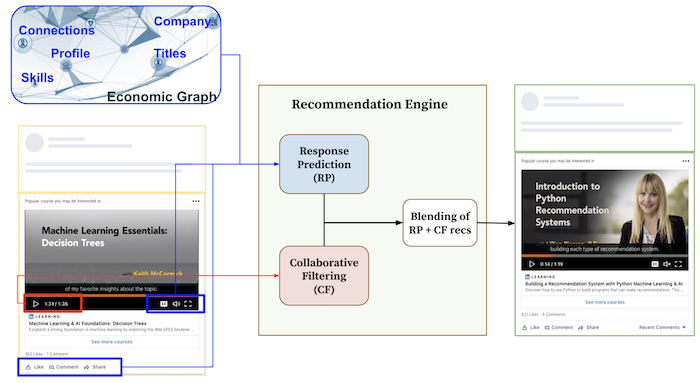
The goal of the course recommendation system is to provide personalized courses to its members so that it helps them advance their professional careers. The recommendation system (Figure 10) consists of three major blocks:
- Collaborative filtering: This block uses collaborative filtering algorithms to recommend courses to a member based on preferences from many users.
- Response prediction: This system predicts the member-course relevance using the learner’s profile features (e.g., skills and industry) and course metadata (e.g., course difficulty, category, and skills).
- Blending: This block combines the recommendations from collaborative filtering and response prediction to determine every learner’s final set of courses. This is an online component, so the offers from each model are fetched upon request.
Collaborative Filtering
Typically there are three collaborative filtering algorithms: user-item-based utility, matrix factorization technique, and deep neural network-based approach. However, due to the popularity and efficacy of deep learning algorithms, LinkedIn adopts a neural collaborative filtering approach (Figure 11) consisting of three networks: course, learner, and output.
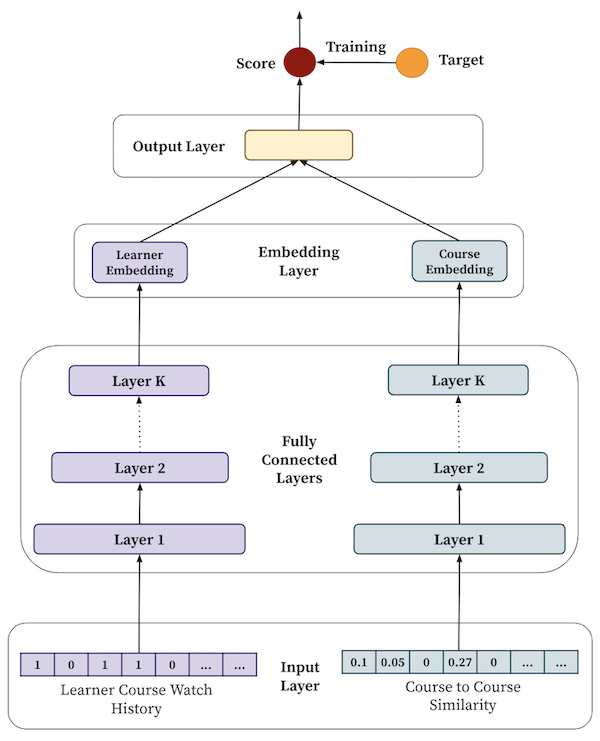
Learner and course networks input course and learner features and generate learner and course embeddings. The output network then computes the ranking score between the learner and course embeddings, which creates a list of course recommendations for each learner.
The input to the learner’s network is a sparse vector of all courses watched by that learner in the past year (Figure 12). For example, for a learner who has watched two courses, the learner input vector will have non-zero values for those courses and zero for others. The input to the course’s network is a vector representing the similarity of that course with other courses (Figure 12). These similarities are computed beforehand based on their co-watching patterns.
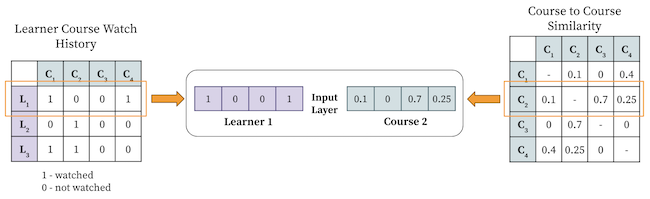
LinkedIn generates binary labels for all learner-course pairs based on historical learner watch history to train the collaborative filtering model. A label of denotes that the course is relevant to the learner, whereas a label of denotes the course is not relevant to the learner.
A course is considered relevant for the learner if the learner has watched the course up to a certain duration. If a learner has only watched the first 10 seconds of a course, that engagement does not impact the model like viewing a full course session.
Response Prediction
Response prediction aims to estimate the relevance of a course for a learner by using learner-level features (e.g., skills, industry, etc.) and course-level features (e.g., course difficulty, course category, and course skills, etc.). LinkedIn uses the Generalized Linear Mixture Model (GLMix) (Figure 13) for response prediction.
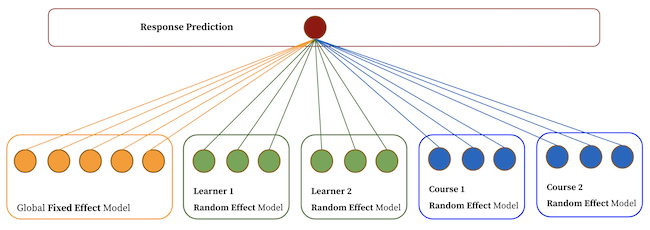
Apart from learning fixed or global model coefficients, GLMix also knows learner-level coefficients based on their engagements with courses and course-level coefficients based on engagement actions of a course. Learning learner and course-level coefficients are important for personalization as they capture the learner’s unique interests.
The predicted score in GLMix is the sum of the three components: global, learner-level, and course-level models.
What’s next? I recommend PyImageSearch University.
80 total classes • 105+ hours of on-demand code walkthrough videos • Last updated: September 2023
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 80 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 80 Certificates of Completion
- ✓ 105+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 520+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson, we discussed LinkedIn recommendation systems. LinkedIn uses AI in ways its members see every day:
- Recommending the right job opportunities
- Encouraging them to connect with someone (“People You May Know” feature)
- Providing relevant content on their feed
- Providing course suggestions to upgrade their skills
- Suggesting recruiters with the best talent for their job openings
We discussed how recommendation systems are used for LinkedIn feeds. The feed is a sorted list of heterogeneous updates (e.g., news, articles, jobs, connections, etc.) displayed to its members when they log in.
The LinkedIn feed recommendation system comprises two engines: First Pass Rankers (FPRs) and Second Pass Rankers (SPRs).
First Pass Rankers are responsible for separately ranking items according to user relevance for each inventory (e.g., articles, news, jobs, connections, etc.). Top-k items from each inventory (ranked by FPRs) are then passed through the Second Pass Ranker (SPR), which combines all these outputs from FPRs to create a single personalized ranked list.
Next, we discussed LinkedIn talent search and recommendations that provide a marketplace to connect job seekers with job providers by enabling recruiters and companies to reach out to potential candidates for their job openings. The talent search and recommendation system learns a function that assigns scores to each candidate based on their relevance to the query provided by the recruiter.
To achieve this, LinkedIn learns dense vector representations of query and member in a common subspace and then performs final scoring afterward. The unsupervised approach involves leveraging the entity graph, a sub-network of the economic graph representing only entities (skill, title, company) whose dense representations need to be learned.
The supervised approach involves learning dense representations for query and member by training neural networks over historically collected query-member pairs and their corresponding binary label (a for member was relevant to the query and also accepted recruiter InMail request and otherwise).
Lastly, we discussed LinkedIn course recommendations that allow members to develop relevant skills through courses to advance their professional careers. The recommendation system consists of two algorithms: collaborative filtering and response prediction.
In collaborative filtering, LinkedIn adopts a neural collaborative filtering approach that takes course and learner features as input and computes the ranking score between the learner and course embeddings, which is used to create a list of course recommendations for each learner.
In response prediction, it uses the Generalized Linear Mixture Model (GLMix) to estimate the relevance of a course for a learner by using learner-level features (e.g., skills, industry, etc.) and course-level features (e.g., course difficulty, course category, and course skills, etc.).
However, this is just the tip of the iceberg, as there is much more to LinkedIn recommendation systems.
Stay tuned for the next sequence of this course series, where we will discuss recommendation systems used on Amazon, YouTube, and Spotify.
Citation Information
Mangla, P. “LinkedIn Jobs Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/9ip27
@incollection{Mangla_2023_LinkedInJobs,
author = {Puneet Mangla},
title = {LinkedIn Jobs Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/9ip27},
}

Unleash the potential of computer vision with Roboflow – Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post LinkedIn Jobs Recommendation Systems appeared first on PyImageSearch.
Find A Teacher Form:
https://docs.google.com/forms/d/1vREBnX5n262umf4wU5U2pyTwvk9O-JrAgblA-wH9GFQ/viewform?edit_requested=true#responses
Email:
public1989two@gmail.com
www.itsec.hk
www.itsec.vip
www.itseceu.uk
Leave a Reply