Table of Contents
Amazon Product Recommendation Systems
In this tutorial, you will learn about Amazon product recommendation systems.

Over the past decade, Amazon has become the first place to look for any product we want. With hundreds of millions of items in its catalog, it has made shopping easy for customers by putting the items they are likely to purchase in front. Everyone who comes to amazon.com sees a different homepage personalized according to his interests and purchases.
Behind the scenes are state-of-the-art recommendation engines that suggest a few products (from a vast catalog) based on your interests, current context, past behavior, and purchases. For example, the app might suggest iPhone covers if you recently purchased an iPhone or are currently looking to purchase one. Another example would be recommending products (e.g., toothpaste, diapers, etc.) based on your purchasing history to promote repeat purchasing.
This lesson will cover several aspects of Amazon recommendations (e.g., related-product recommendations, repeat purchase recommendations, and search recommendations) and how they work behind the scenes.
This lesson is the 1st in a 3-part series on Deep Dive into Popular Recommendation Engines 102:
- Amazon Product Recommendation Systems (this tutorial)
- YouTube Video Recommendation Systems
- Spotify Music Recommendation Systems
To learn how the Amazon recommender systems work, just keep reading.
Amazon Product Recommendation Systems
In this lesson, we will discuss Amazon’s three major recommendation systems: related product, repeat purchase, and query-attribute search recommendations.
Related-Product Recommendations
Recommending related products (Figure 1) to customers is important as it helps them find the right products easily on an e-commerce platform and, at the same time, helps them discover new products, thereby delivering them a great shopping experience. The goal of the related-product recommendation is to recommend top- products that are likely to be bought together with the query product.
products that are likely to be bought together with the query product.
Product Graph
Product Relationships
To formulate the problem statement, let’s assume  ,
,  , and
, and  be any three products and
be any three products and  ,
,  , and
, and  be three binary relationships where:
be three binary relationships where:
 represents that product is co-purchased with product .
represents that product is co-purchased with product . represents that product is co-viewed with product .
represents that product is co-viewed with product . represents that product is similar to product .
represents that product is similar to product .
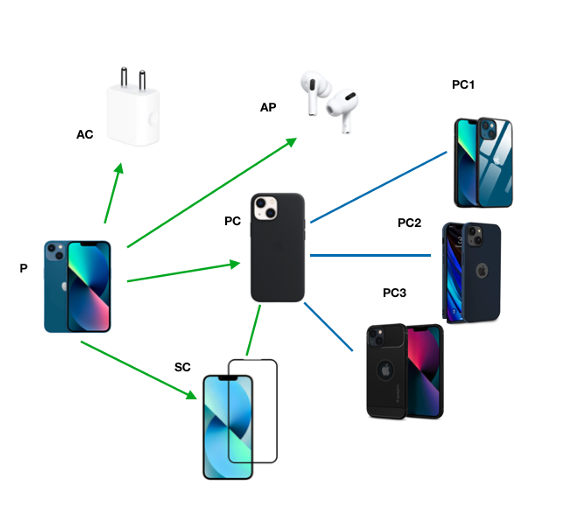
Figure 2 illustrates a product graph where green and blue edges represent co-purchase and co-view edges. AC refers to the adapter, AP refers to AirPods, P refers to iPhone, and PC refers to the phone case. Phone case PC is co-viewed and similar to other phone cases PC1, PC2, and PC3. Note that co-purchase edges are directional as  . This is called the product asymmetry challenge in a related-product recommendation.
. This is called the product asymmetry challenge in a related-product recommendation.
Selection Bias and Cold Start
Along with capturing the asymmetry in the co-purchase relationship, related-product recommendations suffer from the challenge of selection bias, which is inherent to historical purchase data due to product availability, price, etc.
For example, the first customer was presented with phone cases PC and PC1 due to the unavailability of PC2 in their location. At the same time, a second customer was presented with only PC and PC2 because PC1 was out of stock. However, both end up purchasing PC, but that doesn’t mean that PC is a better choice. This creates a selection bias problem.
To mitigate this, we also need to capture second-order relationships of the following types:
Another challenge in related-product recommendations is the cold start problem, where we might also need to suggest newly launched products. Assume is a new product, and and are existing products. To address this, we need to uncover relationships of the following type:
 when is the query product.
when is the query product. when is the related product.
when is the related product.
Graph Construction
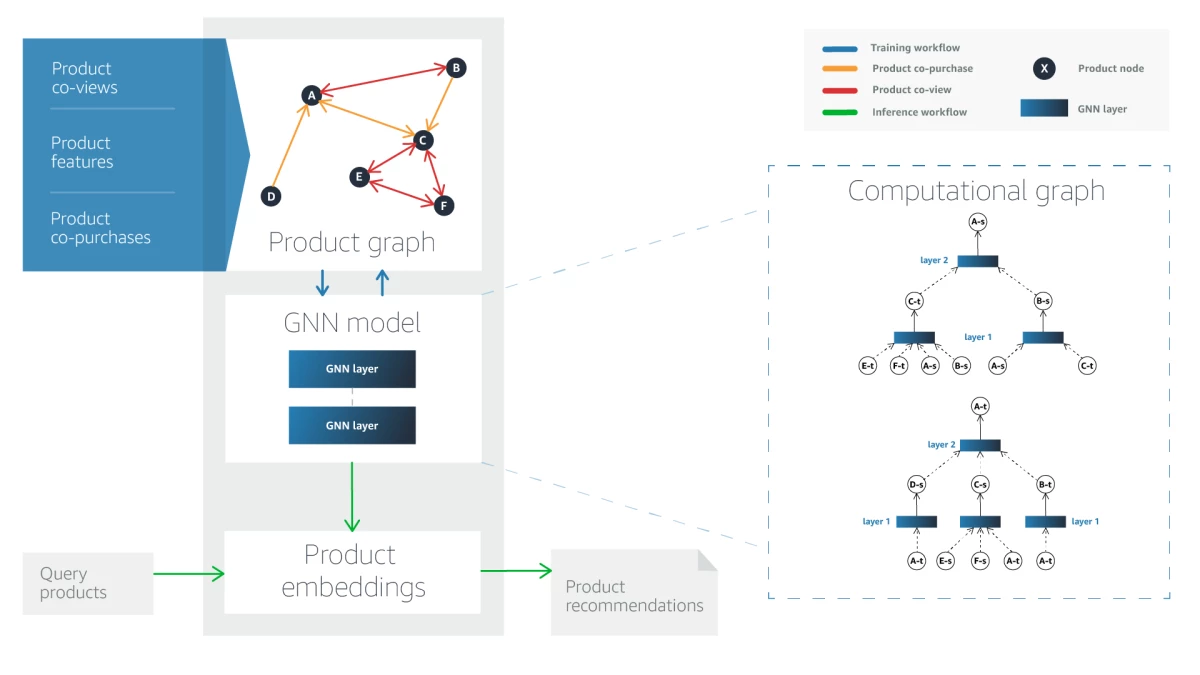
Amazon uses graph neural networks (GNNs) to model these relationships between products by learning their respective product embeddings (Figure 3). Before describing the approach, let’s look at how the product graph is constructed.
The product graph  consists of a set of vertices
consists of a set of vertices  that represents products.
that represents products.  represents the set of co-purchase edges (i.e.,
represents the set of co-purchase edges (i.e.,  | \forall u,v \in P \land uR_\text{cp}v \}") ).
).
However, is prone to selection bias and might miss relationships of type  and
and  .
.
To address this, we also include  which represents the set of co-viewed edges (i.e.,
which represents the set of co-viewed edges (i.e.,  | \forall u,v \in P \land uR_\text{cv}v \}") ).
).
With this, graph  now handles asymmetry and selection bias by containing the following product relationships:
now handles asymmetry and selection bias by containing the following product relationships:
- Asymmetry:
- Selection bias:
- Selection bias:
Figure 4 illustrates what a product graph looks like.
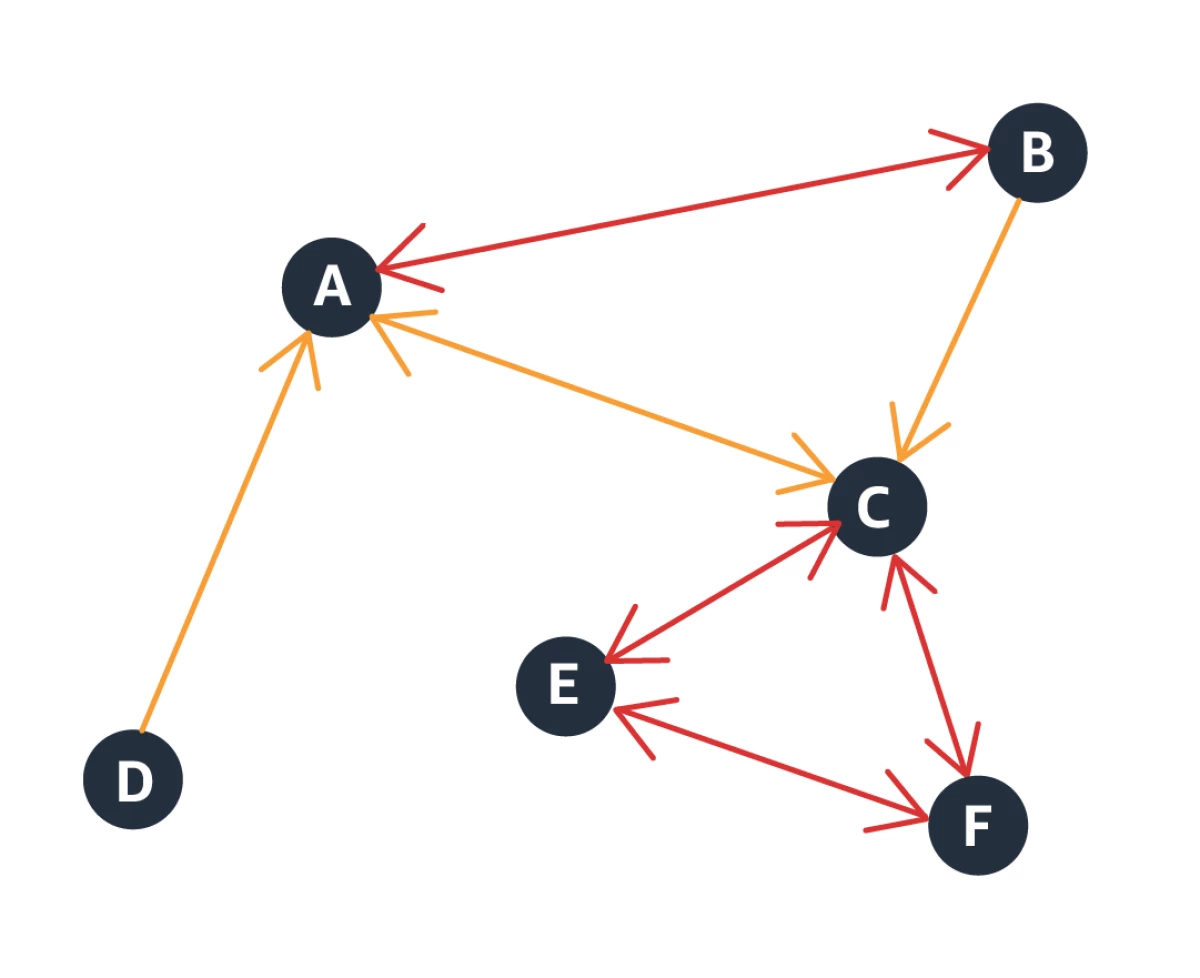
Product Embedding Generation: Forward Pass
Algorithm
The GNN approach learns two embeddings for each product: source and target. Source and target embeddings are used when the product is a query and recommended item, respectively.
Algorithm 1 explains the procedure for generating these embeddings. Let ^l") and
and ^l") denote the source and target embedding for product
denote the source and target embedding for product  at the
at the  step in the algorithm. These embeddings are initialized with their respective product input features.
step in the algorithm. These embeddings are initialized with their respective product input features.

First, the algorithm extracts the co-purchase and co-view neighbors for each product . The source embedding of product at the step (i.e., ) is computed as a linear combination of two non-linear terms (Line 4 of Algorithm 1).
The first term is the non-linear aggregation of target representations of its co-purchase neighbors at the ^\text{th}") step. Similarly, the second term is the non-linear aggregation of target representations of its co-viewed neighbors at the step. In other words,
step. Similarly, the second term is the non-linear aggregation of target representations of its co-viewed neighbors at the step. In other words,
^l \leftarrow \text{ReLU} \left (\sum_{(u,v) \in E_\text{cp}} (h^t_v)^{l-1} W^l \right) + \text{ReLU} \left (\sum_{(u,v) \in E_\text{cv}} (h^t_v)^{l-1} W^l \right),")
where  is ReLU activation, and
is ReLU activation, and  are weights of a fully connected layer at step
are weights of a fully connected layer at step  .
.
We do similar things for generating target representation of each product (Line 5 of Algorithm 1). The source and target embeddings are then normalized (Lines 7 and 8 of Algorithm 1) to the unit norm, and this process is repeated till  steps to generate the final source and target embeddings
steps to generate the final source and target embeddings  and
and  for each product .
for each product .
Related-Product Recommendation
Given a query product  and its source embedding
and its source embedding  , we perform a nearest neighbor lookup in target embedding space and recommend top- products. The relevance or utility score
, we perform a nearest neighbor lookup in target embedding space and recommend top- products. The relevance or utility score ") of a candidate product
of a candidate product  with respect to query product is calculated as:
with respect to query product is calculated as:
 \ = \ (\theta^s_q)^T(\theta^t_v)")
Note that  \neq \text{relevance}(v, q)") , which helps us capture the asymmetry in co-purchase relationships.
, which helps us capture the asymmetry in co-purchase relationships.
Given a cold-start product , we perform a neighbor lookup to identify similar products  in the input product feature space. Then we augment the product graph with new edges
in the input product feature space. Then we augment the product graph with new edges , (c, c_2), \dots, (c, c_k)\}") and pass the sub-graph corresponding to product to Algorithm 1 to generate its source and target embeddings. These embeddings are then used in the same way to compute the utility score.
and pass the sub-graph corresponding to product to Algorithm 1 to generate its source and target embeddings. These embeddings are then used in the same way to compute the utility score.
Loss Function and Training
To learn the fully connected layer parameters  , we use an asymmetric loss function, as shown in Figure 5.
, we use an asymmetric loss function, as shown in Figure 5.
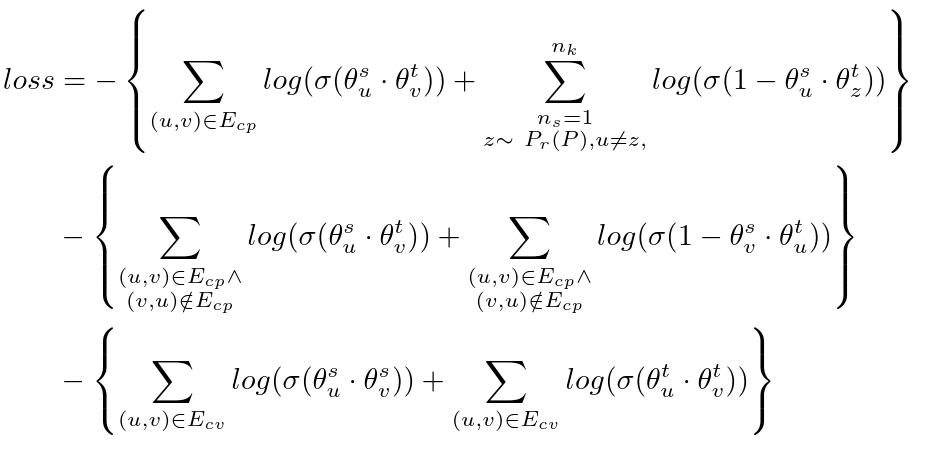
The loss function contains three terms:
- The first term in the loss function is a combination of two sub-terms. The first sub-term ensures that the source embedding of a product and the target embedding of its co-purchased product are similar.
In contrast, the second sub-term ensures that the source embedding of a product
and the target embedding of a randomly selected product are dissimilar.
- The second term ensures asymmetry by assigning a high score to a co-purchased pair
 \in E_\text{cp}") and a low score to pair
and a low score to pair  \notin E_\text{cp}") .
.
- The third term ensures that co-viewed product pairs’ source and target embeddings are similar. This helps mitigate selection bias as if products and are co-viewed, then
 \approx \text{relevance}(q,v)") for an arbitrary query product .
for an arbitrary query product .
Repeat Purchase Recommendations
Repeat purchasing (i.e., a customer purchasing the same product multiple times) is an important phenomenon in e-commerce platforms (Figure 6). Modeling repeat purchases helps businesses increase their product click-through rate and makes the shopping experience easy for customers.
Repeat purchase recommendations estimate the probability of a customer purchasing a product again as a function of time from their last purchase. In other words, given a customer  has already purchased a product
has already purchased a product  -times with time intervals
-times with time intervals  , we want to estimate the purchase probability density:
, we want to estimate the purchase probability density:
")
In the above equation, we assume that the product purchases are independent of each other, and the equation can be decomposed into two components:
 \approx Q(A_i) \times R_{A_i}(t_{k+1} = t | t_1, t_2, \dots, t_k, A_i=1),")
where ") is the repeat purchase probability of a customer buying a product a
is the repeat purchase probability of a customer buying a product a ^\text{th}") time given that they have bought it times.
time given that they have bought it times.  is the distribution of
is the distribution of  , conditioned on the customer repurchasing that product; indicated by
, conditioned on the customer repurchasing that product; indicated by  .
.
This lesson will discuss three frameworks Amazon uses to model repeat purchases.
Repeat Customer Probability Model
This framework is time-independent and is based on a frequency-based probabilistic model that computes the repeat customer probability ") for each product by using aggregate repeat purchase statistics of products by customers. In other words, it assumes that
for each product by using aggregate repeat purchase statistics of products by customers. In other words, it assumes that  and
and  \approx Q(A_i) \approx \text{RCP}(A_i)") .
.
 \ = \ \displaystyle\frac{\text{\#s of customers who bought product } A_i \text{ more than once}}{\text{\#s of customers who bought product } A_i \text{ at least once}}")
To ensure good quality of repeat product recommendations, we only recommend products for which  > r_\text{threshold}") , where
, where  is an operating threshold.
is an operating threshold.
Aggregate Time Distribution Model
Amazon analysis shows that most customers have only a few repeat purchases for a specific product (i.e., is low). But there are many products for which Amazon has many customers making repeat purchases (i.e., is high). Hence repeat purchases often depend on a customer’s purchase behavior.
Aggregate time distribution (ATD) model is a time-based model that assumes that product purchase density is only a function of past purchase behavior . In other words,  and
and  \approx R_{A_i}(t_{k+1} = t | t_1, t_2, \dots, t_k, A_i=1)") .
.
Amazon uses a log-normal distribution for defining :
 = \mathcal{N}(\ln(t); \mu_i, \sigma_i),")
where  and
and  are the mean and variance of the Gaussian distribution.
are the mean and variance of the Gaussian distribution.
Figure 7 illustrates the distribution of repeat purchase time intervals ( ) and log repeat purchase time intervals (
) and log repeat purchase time intervals (") ) of a random consumable product across all its repeat purchasing customers.
) of a random consumable product across all its repeat purchasing customers.

Note that only the products having are deemed repeat purchasable and vice versa. Finally, recommendations are generated by considering all the repeat purchasable products previously bought by customers and ranking them in the descending order of their estimated probability density ") at a given time .
at a given time .
Poisson-Gamma Model
Poisson-gamma (PG) model is one of the most seminal works in modeling customer repeat purchases. It assumes the following two assumptions:
- A customer’s repeat purchases follow a homogeneous Poisson process (Figure 8) with a repeat purchase rate
 . In other words, they assume that successive repeat purchases are not correlated.
. In other words, they assume that successive repeat purchases are not correlated. - Assume a gamma prior on (i.e., assume that across all customers follows a Gamma distribution with shape
 and rate
and rate  ).
).

The parameters and of the gamma distribution can be estimated using maximum likelihood estimation over the purchase rates of repeat customers. After this, the purchase rate  for a customer and product is given as:
for a customer and product is given as:

where  and
and  are the shape and rate parameters of gamma distribution for product , is the number of repeat purchases, and is the time elapsed since the first purchase of product by customer .
are the shape and rate parameters of gamma distribution for product , is the number of repeat purchases, and is the time elapsed since the first purchase of product by customer .
The is then assumed to be a Poisson distribution where the rate parameter is estimated using the above equation.
 \ = \ \displaystyle\sum_{m=1}^{\infty} \displaystyle\frac{\lambda^m_{A_i, C} \exp(\lambda_{A_i, C})}{m!}")
where  is the expected number of purchases, this model assumes that
is the expected number of purchases, this model assumes that  is fixed, just like the ATD approach.
is fixed, just like the ATD approach.
Query-Attribute Search Recommendation
Amazon search queries are mostly related to products and are often short (three to four words) and not too descriptive. Such short and undescriptive queries can lead to suboptimal search results because of an information shortage. Amazon leverages attribute recommendations to improve the quality of search recommendations for short queries.
The attribute recommendation (Figure 9) takes the customer query as input and recommends implicit attributes that don’t explicitly appear in the search query. For example, for a search query “iphone 8,” the attribute recommendation will suggest additional attributes like “brand:apple,” “operating_system:ios,” “complements: phone case,” and “substitute_brand: samsung.” These additional attributes can enrich the search query and help the search engine provide better results.

The attribute recommendation model comprises three modules: query intent classification, explicit attribute recognition, and implicit attribute recommendation. We will now describe each of these in detail.
Query Intent Classification
The intent of a query is defined as the product type intent of the question. For example, the intent of the query “iPhone 14” is “phone,” and for “Nike shoes,” it is “shoes.” Amazon has more than 3000 product types; hence, it is posed as a multi-label classification where a query intent can be classified into one or more product types.
Given a query and country id , the model predicts whether each product type is relevant to the question. For training, Amazon uses past customer click behavior from the search logs. These logs contain the number of clicks on each product for a country and query pair.
Each product is assigned a product type  from a catalog . Each country-query pair
from a catalog . Each country-query pair ") is assigned a label,
is assigned a label,

where  is the number of clicks on product for query
is the number of clicks on product for query  .
.
As shown in Figure 10, the module uses a BERT (bidirectional encoder representations from transformers) model, which performs classification on top of classification token ([CLS]) output embedding. Since it’s a multi-country setting, each country has a different label space consisting of labels observed for products in that marketplace. Hence, we only get labels corresponding to that country’s marketplace. The architecture is shown in the figure below.
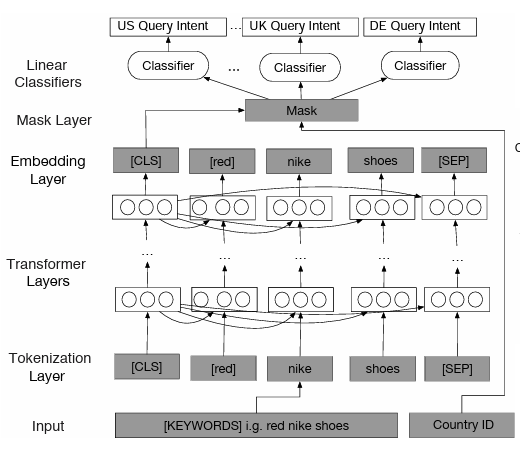
Explicit Attribute Parsing
Explicit attribute parsing involves recognizing product attributes from the query (e.g., color, brand, etc.). This module uses a multilingual transformer-based model that performs recognition, as shown below. Each token goes through classification to get its classification label, denoting what attribute this token belongs to. This is illustrated in Figure 11:

Implicit Attribute Recommendation
This module first builds an attribute relation graph using two data sources: Amazon product attributes and query attributes. Amazon product attributes are the explicit attributes sellers provide while uploading the product on their platform. For example, iPhone 8 has the attribute brand “apple” and product type “phone.”
The query attribute data is collected from customer search queries, and their corresponding explicit attributes are extracted using the parsing module described before.
Then, the intent classification model obtains each query’s product intent, and each product’s intent is naturally obtained through catalog data. All this information is then used to construct the attribute relation graph shown in Figure 12.
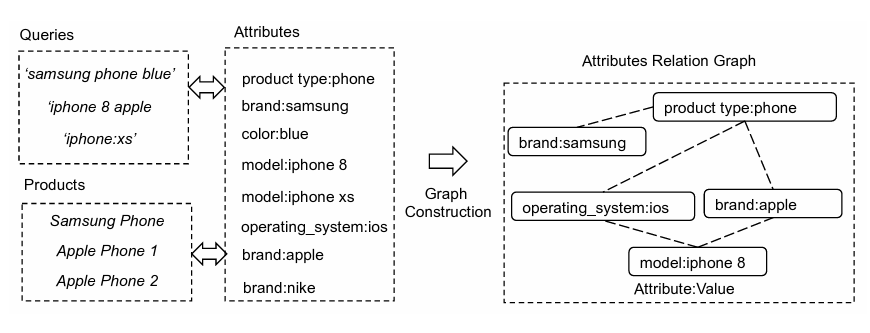
The module used GNN to generate embeddings for each attribute. These embeddings are then used to construct relationships between different attributes. During online inference, given the explicit query attributes and intent, we use the attribute relation graph to recommend implicit attributes by doing a random walk through the graph.
What’s next? I recommend PyImageSearch University.
80 total classes • 105+ hours of on-demand code walkthrough videos • Last updated: September 2023
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 80 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 80 Certificates of Completion
- ✓ 105+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 520+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson, we discussed three Amazon recommender systems:
- related-product recommendation
- repeat purchase recommendation
- query attribute recommendation
The goal of the related-product recommendation is to recommend top- products that are likely to be bought together with the query product. Amazon creates a product graph whose vertices denote all the products and whose edges represent co-purchase (directed) and co-viewed (undirected) relationships.
Graph neural networks (GNNs) are used to learn source and target embeddings for each product based on their relationships. The relevance of a candidate product with respect to the query product is calculated as the dot product between the source representation of the query product and the target representation of the candidate product.
Next, repeat purchase recommendations estimate the probability of a customer purchasing a product again as a function of time from their last purchase of that product. Amazon uses three probabilistic models for modeling repeat purchases.
- The repeat customer probability model is a time-independent framework based on a frequency-based probabilistic model that computes the repeat customer probability for each product using aggregate repeat purchase statistics of products by customers.
- The aggregate time distribution (ATD) model is a time-based model that assumes that product purchase density is only a function of past purchase behavior.
- The Poisson-gamma (PG) model takes customers’ repeat purchases following a homogeneous Poisson process, and the purchase rate across all customers follows a Gamma distribution.
Lastly, the attribute recommendation takes the customer query as input and recommends implicit attributes that don’t explicitly appear in the search query. The attribute recommendation model comprises three modules:
- query intent classification
- explicit attribute recognition
- implicit attribute recommendation
The intent classification model predicts whether each product type is relevant to the query. Explicit attribute parsing involves recognizing product attributes like color, brand, etc., from the query. Finally, the implicit attribute recommendation model builds an attribute relation graph using two data sources: amazon product attributes and query attributes.
However, this is just the tip of the iceberg. There is much more to the Amazon recommendation systems. We highly recommend going through their blog page to learn more.
Stay tuned for an upcoming lesson on YouTube video recommendation systems!
Citation Information
Mangla, P. “Amazon Product Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/m8ps5
@incollection{Mangla_2023_Amazon_Product_Recommendation_Systems,
author = {Puneet Mangla},
title = {Amazon Product Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/m8ps5},
}

Unleash the potential of computer vision with Roboflow – Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post Amazon Product Recommendation Systems appeared first on PyImageSearch.
Find A Teacher Form:
https://docs.google.com/forms/d/1vREBnX5n262umf4wU5U2pyTwvk9O-JrAgblA-wH9GFQ/viewform?edit_requested=true#responses
Email:
public1989two@gmail.com
www.itsec.hk
www.itsec.vip
www.itseceu.uk
Leave a Reply