In this guide, let’s delve into preparing a dataset of Wikipedia articles for search, utilizing the OpenAI API. The process involves
- downloading Wikipedia articles related to a particular topic,
- chunking the downloaded documents into smaller sections suitable for embedding,
- generating the embeddings using OpenAI, and finally,
- storing the embedded sections for future use.
In case you need a quick refresher on OpenAI embeddings, feel free to read through our Finxter article here: 

 Recommended: What Are Embeddings in OpenAI?
Recommended: What Are Embeddings in OpenAI?
Prerequisites
Before starting, ensure that you have all the necessary libraries installed. The libraries include mwclient for fetching Wikipedia articles, mwparserfromhell for parsing Wikipedia articles, openai for creating the embeddings, pandas for data management, regex for text cleaning, and tiktoken for analyzing token counts.
Use pip as shown below:
pip install mwclient mwparserfromhell openai pandas regex tiktoken
If you’re using Google Colab, you can run the following:
pip install mwclient mwparserfromhell openai pandas regex tiktoken
Restart your Python environment after installing the libraries to incorporate the changes effectively. As a reference, we used this guide from the Cookbook as a starting point for this article.
Copy and Paste Code: If you want to get the whole code for copy and paste, scroll down to the end of this article where I have refactored the code to one big copy and pastable code snippet you can run in Google Colab, for example.
4 Steps to Create an Embedding From a Set of Wikipedia Articles

The following is a step-by-step guide on how to prepare a dataset of Wikipedia articles for search:
Step 1: Collect Documents
First, you need to download your set of Wikipedia articles related to your chosen topic. For this tutorial, we will download a few articles related to Artificial Intelligence, i.e., "Category:Artificial intelligence". You can replace everything after Category: with your specific category.
Note: Category names in Wikipedia are case sensitive, so "Category:Artificial intelligence" works while "Category:Artificial Intelligence" won’t work.
You can use the mwclient library function to obtain the article titles.
import mwclient
CATEGORY_TITLE = "Category:Artificial intelligence"
WIKI_SITE = "en.wikipedia.org"
def titles_from_category(category: mwclient.listing.Category, max_depth: int) -> set[str]:
"""
Return a set of page titles in a given Wiki category and its subcategories.
:param category: The Wiki category to retrieve titles from.
:param max_depth: The maximum depth to search for subcategories.
:return: A set of page titles.
"""
titles = set()
for member in category.members():
if isinstance(member, mwclient.page.Page):
titles.add(member.name)
elif isinstance(member, mwclient.listing.Category) and max_depth > 0:
titles.update(titles_from_category(member, max_depth=max_depth - 1))
return titles
site = mwclient.Site(WIKI_SITE)
category_page = site.pages[CATEGORY_TITLE]
titles = titles_from_category(category_page, max_depth=1)
print(titles)
In my case, the output is a lengthy:
{'Embodied cognitive science', 'Category:Cloud robotics', 'Software agent', 'Reinforcement learning from human feedback', 'Synthetic media', 'Schema-agnostic databases', 'Blended artificial intelligence', 'Argumentation framework', 'Category:Artificial intelligence laboratories', 'Action selection', 'IJCAI Computers and Thought Award', 'Category:Chatbots', 'Weak artificial intelligence', 'AZFinText', 'Embodied agent', 'Hardware for artificial intelligence', 'SUPS', 'Machine perception', 'Hi! PARIS', 'Knowledge level', 'Joint Artificial Intelligence Center', 'Enterprise cognitive system', 'Human Problem Solving', 'Batch normalization', 'Summit on Responsible Artificial Intelligence in the Military Domain', 'Intelligent information society', 'Alignment Research Center', 'Percept (artificial intelligence)', 'Category:Fiction about artificial intelligence', 'Computer audition', 'Adobe Enhanced Speech', 'AI Superpowers', 'Attributional calculus', 'Automated negotiation', 'Intelligent agent', 'Mindpixel', 'Data-driven model', 'Incremental heuristic search', 'Category:Rule engines', 'Knowledge-based recommender system', 'Pedagogical agent', 'Personality computing', 'Category:Artificial intelligence art', 'Category:Automated reasoning', 'Category:Knowledge representation', 'Algorithmic probability', 'Edmond de Belamy', 'Psychology of reasoning', 'Artificial intelligence detection software', 'Category:Artificial intelligence publications', 'Computational heuristic intelligence', 'Neurorobotics', 'Nouvelle AI', 'Category:Machine learning', 'Situated approach (artificial intelligence)', 'AI alignment', 'Wetware (brain)', 'Hybrid intelligent system', 'Admissible heuristic', 'Category:Artificial intelligence conferences', 'Progress in artificial intelligence', 'INDIAai', 'Thompson sampling', 'Belief–desire–intention model', 'Syman', 'Category:Ambient intelligence', 'Artificial intelligence in healthcare', 'Computer Science Ontology', 'Synthography', 'Non-human', 'Artificial intelligence arms race', 'Empowerment (artificial intelligence)', 'Business process automation', 'Automated Mathematician', 'MindsDB', 'Intelligent decision support system', 'Diagnosis (artificial intelligence)', 'Virtual intelligence', 'Computational humor', 'Histogram of oriented displacements', 'Category:Virtual assistants', 'Interim Measures for the Management of Generative AI Services', 'Anytime algorithm', 'Category:Artificial intelligence templates', 'Principle of rationality', 'Remi El-Ouazzane', 'Symbol level', 'Artificial intelligence and copyright', 'Artificial reproduction', 'Brain technology', 'Category:Argument technology', 'Category:Philosophy of artificial intelligence', 'Category:Distributed artificial intelligence', 'Intelligent database', 'The Fable of Oscar', 'Category:Existential risk from artificial general intelligence', 'Category:Multi-agent systems', 'Artificial psychology', 'Intrinsic motivation (artificial intelligence)', 'Means–ends analysis', 'Smart object', 'Category:Cognitive architecture', 'Frame problem', 'A.I. Insight forums', 'Dynamic epistemic logic', 'Stewart Nelson', 'AGI (computer science)', 'Belief–desire–intention software model', 'Case-based reasoning', 'Frame language', 'Google Clips', 'Description logic', 'Oriented energy filters', 'Elements of AI', 'Category:Artificial intelligence stubs', 'Intelligent word recognition', 'OpenIRIS', 'Algorithmic accountability', 'Workplace impact of artificial intelligence', 'International Conference on Autonomous Agents and Multiagent Systems', 'POP-11', 'Microsoft 365 Copilot', 'Perusall', 'Aurora (novel)', 'Graphics processing unit', 'Problem solving', 'Category:Applications of artificial intelligence', 'Category:AI accelerators', 'K-line (artificial intelligence)', 'Winner-take-all in action selection', 'Information space analysis', 'Pattern theory', 'Autonomic networking', 'Computational intelligence', 'Behavior informatics', 'Fine-tuning (deep learning)', 'Symbolic artificial intelligence', 'Vaumpus world', 'Mivar-based approach', 'Category:Artificial intelligence competitions', 'Autonomous agent', 'Artificial intelligence industry in China', 'Connectionist expert system', 'Omar Al Olama', 'Category:Works created using artificial intelligence', 'CarynAI', 'Knowledge compilation', 'Category:Fuzzy logic', 'Epistemic modal logic', 'Lifelong Planning A*', 'Operational artificial intelligence', 'Category:Open-source artificial intelligence', 'Category:Mind–body problem', 'Structure mapping engine', 'Maia and Marco', 'Thomas Bolander', 'AI-complete', 'Data Science and Predictive Analytics', 'Prompt engineering', 'ASI (computer science)', 'Ensemble averaging (machine learning)', 'Artificial intelligence', 'Neural computation', 'Evolutionary developmental robotics', 'Category:Game artificial intelligence', 'Intelligent control', 'Category:Signal processing conferences', 'Concurrent MetateM', 'Artificial consciousness', 'Hallucination (artificial intelligence)', 'Generative artificial intelligence', 'Category:AI software', 'Category:Artificial intelligence entertainment', 'Michael Apter', 'Category:Affective computing', 'Neuro-symbolic AI', 'List of programming languages for artificial intelligence', 'Data pack', 'Gödel machine', 'Category:AI companies', 'Character computing', 'Neural architecture search', 'AI boom', 'Artificial wisdom', 'AI safety', 'Parallel Intelligence', 'Quantum artificial life', 'Category:History of artificial intelligence', 'Computational human modeling', 'Anticipation (artificial intelligence)', 'Explainable artificial intelligence', 'Knowledge-based systems', 'Agent systems reference model', 'Probabilistic logic network', 'LangChain', 'Artificial general intelligence', 'Behavior selection algorithm', "Roko's basilisk", 'KL-ONE', 'Auto-GPT', 'Artificial intelligence in industry', 'Text-to-video model', 'Babelfy', 'Cognitive philology', 'Web intelligence', 'Blackboard system', 'Game theory', 'Category:Artificial immune systems', 'Category:Computer vision', 'Category:Artificial intelligence people', 'National Security Commission on Artificial Intelligence', 'Knowledge-based configuration', 'Universal psychometrics', 'AI-assisted virtualization software', 'Gender digital divide', 'Grammar systems theory', 'Operation Serenata de Amor', 'Category:Artificial intelligence associations', 'Artificial intelligence in fraud detection', 'Autonomic computing', 'Personoid', 'Situated', 'Autognostics', 'DABUS', 'Data processing unit', 'Hierarchical control system', 'GOLOG', 'KAoS', 'Bayesian programming', 'Karen Hao', 'And–or tree', 'Commonsense knowledge (artificial intelligence)', 'Hindsight optimization', 'Wadhwani Institute for Artificial Intelligence', 'Wetware computer', 'Category:Neural networks', 'Zeuthen strategy', 'Category:Evolutionary computation', 'Extremal optimization', 'Category:Generative artificial intelligence', 'Category:Turing tests', "Gabbay's separation theorem", 'Spreading activation', 'ASR-complete', 'Self-management (computer science)', 'Emergent algorithm', 'Fuzzy agent', 'Language/action perspective', 'Cognitive computing', 'Halite AI Programming Competition'}
Step 2: Chunk Documents

The next step is to divide the Wikipedia articles into smaller sections conducive to embedding. It is important to disregard sections like 'External Links' and 'Footnotes' as they lack context. Clean up the text by removing unnecessary tags, whitespace, and short sections.
You can copy and paste the following code, however make sure you have initialized the titles variable as shown in the previous Step 1. I’ll also give the full code at the end of this article.
import regex as re
import mwclient
import mwparserfromhell
SECTIONS_TO_IGNORE = set([
"See also", "References", "External links", "Further reading", "Footnotes",
"Bibliography", "Sources", "Citations", "Literature", "Notes and references",
"Photo gallery", "Works cited", "Photos", "Gallery", "Notes",
"References and sources", "References and notes",
])
WIKI_SITE = 'en.wikipedia.org'
def all_subsections_from_section(section, parent_titles, sections_to_ignore):
headings = [str(h) for h in section.filter_headings()]
title = headings[0].strip("= ").strip()
if title in sections_to_ignore:
return []
titles = parent_titles + [title]
section_text = str(section).split(title, 1)[1]
if len(headings) == 1:
return [(titles, section_text)]
first_subtitle = headings[1]
section_text = section_text.split(first_subtitle, 1)[0]
results = [(titles, section_text)]
for subsection in section.get_sections(levels=[len(titles) + 1]):
results.extend(all_subsections_from_section(subsection, titles, sections_to_ignore))
return results
def all_subsections_from_title(title, sections_to_ignore=SECTIONS_TO_IGNORE, site_name=WIKI_SITE):
site = mwclient.Site(site_name)
page = site.pages[title]
parsed_text = mwparserfromhell.parse(page.text())
headings = [str(h) for h in parsed_text.filter_headings()]
summary_text = str(parsed_text).split(headings[0], 1)[0] if headings else str(parsed_text)
results = [([title], summary_text)]
for subsection in parsed_text.get_sections(levels=[2]):
results.extend(all_subsections_from_section(subsection, [title], sections_to_ignore))
return results
def clean_section(section):
titles, text = section
text = re.sub(r"<ref.*?</ref>", "", text).strip()
return titles, text
def keep_section(section):
_, text = section
return len(text) >= 16
def process_titles(titles):
wikipedia_sections = []
for title in titles:
wikipedia_sections.extend(all_subsections_from_title(title))
wikipedia_sections = [clean_section(ws) for ws in wikipedia_sections]
original_num_sections = len(wikipedia_sections)
wikipedia_sections = [ws for ws in wikipedia_sections if keep_section(ws)]
print(f"Filtered out {original_num_sections - len(wikipedia_sections)} sections, leaving {len(wikipedia_sections)} sections.")
return wikipedia_sections
# Example usage
# titles = see previous cell
wikipedia_sections = process_titles(titles)
for ws in wikipedia_sections[:5]:
print(ws[0])
print(ws[1][:77] + "...")
 Explanation:
Explanation:
This code extracts and cleans text sections from a list of Wikipedia page titles and stores it in the variable wikipedia_sections for further processing.
It navigates through each title, fetching the associated page content and breaking it down into sections and subsections. It ignores specified sections like “See also” and “References.”
The text from each relevant section is extracted, and any citation references are removed. The code then filters out any sections with text shorter than 16 characters.
The cleaned and filtered text sections are then outputted.
In my case the output is:
Filtered out 68 sections, leaving 1408 sections.
['Embodied cognitive science']
{{Short description|Interdisciplinary field of research}}
{{for|approaches to...
['Embodied cognitive science', 'Contributors']
==
Embodied cognitive science borrows heavily from [[embodied philosophy]] an...
['Embodied cognitive science', 'Traditional cognitive theory']
==
Embodied cognitive science is an alternative theory to cognition in which...
['Embodied cognitive science', 'The embodied cognitive approach']
==
Embodied cognitive science differs from the traditionalist approach in th...
['Embodied cognitive science', 'The embodied cognitive approach', 'Physical attributes of the body']
===
The first aspect of embodied cognition examines the role of the physical ...
Info: The important element obtained from the previous processing is a condensed information base stored in the variable wikipedia_sections.
Next, you’ll employ a recursive approach to divide lengthy sections into smaller ones.
Splitting text into sections doesn’t have a one-size-fits-all solution, and it involves various trade-offs:
- While longer sections provide more context for questions, they may hinder retrieval by combining multiple topics, leading to confusion.
- Shorter sections are cost-effective (as costs are tied to the number of tokens) and enhance retrieval by allowing more sections to be accessed, potentially improving recall.
- Utilizing overlapping sections can avert answers from being truncated by section boundaries.
In this scenario, we opt for a straightforward strategy, capping each section at 1,600 tokens. We recursively divide any exceeding sections into halves. To prevent the disruption of meaningful sentences, the division is preferably done along paragraph boundaries.
Now copy and paste the following (again make sure the variable wikipedia_section is properly initialized as shown in the code snippet before, or simply copy and paste the full code at the end of this article):
import tiktoken
GPT_MODEL = "gpt-3.5-turbo" # which tokenizer to use?
def num_tokens(text: str, model: str = GPT_MODEL) -> int:
"""Return the number of tokens in a string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def halved_by_delimiter(string: str, delimiter: str = "\n") -> list[str, str]:
"""Split a string in two, on a delimiter, trying to balance tokens on each side."""
chunks = string.split(delimiter)
if len(chunks) == 1:
return [string, ""] # no delimiter found
elif len(chunks) == 2:
return chunks # no need to search for halfway point
else:
total_tokens = num_tokens(string)
halfway = total_tokens // 2
best_diff = halfway
for i, chunk in enumerate(chunks):
left = delimiter.join(chunks[: i + 1])
left_tokens = num_tokens(left)
diff = abs(halfway - left_tokens)
if diff >= best_diff:
break
else:
best_diff = diff
left = delimiter.join(chunks[:i])
right = delimiter.join(chunks[i:])
return [left, right]
def truncated_string(
string: str,
model: str,
max_tokens: int,
print_warning: bool = True,
) -> str:
"""Truncate a string to a maximum number of tokens."""
encoding = tiktoken.encoding_for_model(model)
encoded_string = encoding.encode(string)
truncated_string = encoding.decode(encoded_string[:max_tokens])
if print_warning and len(encoded_string) > max_tokens:
print(f"Warning: Truncated string from {len(encoded_string)} tokens to {max_tokens} tokens.")
return truncated_string
def split_strings_from_subsection(
subsection: tuple[list[str], str],
max_tokens: int = 1000,
model: str = GPT_MODEL,
max_recursion: int = 5,
) -> list[str]:
"""
Split a subsection into a list of subsections, each with no more than max_tokens.
Each subsection is a tuple of parent titles [H1, H2, ...] and text (str).
"""
titles, text = subsection
string = "\n\n".join(titles + [text])
num_tokens_in_string = num_tokens(string)
# if length is fine, return string
if num_tokens_in_string <= max_tokens:
return [string]
# if recursion hasn't found a split after X iterations, just truncate
elif max_recursion == 0:
return [truncated_string(string, model=model, max_tokens=max_tokens)]
# otherwise, split in half and recurse
else:
titles, text = subsection
for delimiter in ["\n\n", "\n", ". "]:
left, right = halved_by_delimiter(text, delimiter=delimiter)
if left == "" or right == "":
# if either half is empty, retry with a more fine-grained delimiter
continue
else:
# recurse on each half
results = []
for half in [left, right]:
half_subsection = (titles, half)
half_strings = split_strings_from_subsection(
half_subsection,
max_tokens=max_tokens,
model=model,
max_recursion=max_recursion - 1,
)
results.extend(half_strings)
return results
# otherwise no split was found, so just truncate (should be very rare)
return [truncated_string(string, model=model, max_tokens=max_tokens)]
# split sections into chunks
MAX_TOKENS = 1600
wikipedia_strings = []
for section in wikipedia_sections:
wikipedia_strings.extend(split_strings_from_subsection(section, max_tokens=MAX_TOKENS))
print(f"{len(wikipedia_sections)} Wikipedia sections split into {len(wikipedia_strings)} strings.")
# print example data
print(wikipedia_strings[1])
Explanation:
This Python code is used for processing and truncating text data, specifically focusing on splitting and tokenizing strings.
It uses the tiktoken library to count the number of tokens in a text string for a given model (default is "gpt-3.5-turbo").
The halved_by_delimiter function splits a string into two parts based on a delimiter, aiming to balance the number of tokens in each part.
The truncated_string function shortens a string to a specified maximum number of tokens, issuing a warning if truncation occurs.
The split_strings_from_subsection function recursively splits a subsection of text to ensure that each resulting piece has no more than a specified number of tokens. It tries different delimiters and falls back to truncation if no suitable split is found.
The code concludes by applying these functions to a list of Wikipedia sections, splitting them into chunks with a maximum token limit, and printing out the results.
In my case the output is AI related due to the artificial intelligence articles specified above:
/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)
1408 Wikipedia sections split into 1420 strings.
Embodied cognitive science
Contributors
==
Embodied cognitive science borrows heavily from [[embodied philosophy]] and the related research fields of [[cognitive science]], [[psychology]], [[neuroscience]] and [[artificial intelligence]]. Contributors to the field include:
* From the perspective of neuroscience, [[Gerald Edelman]] of the [[Neurosciences Institute]] at La Jolla, [[Francisco Varela]] of [[CNRS]] in France, and [[J. A. Scott Kelso]] of [[Florida Atlantic University]]
* From the perspective of psychology, [[Lawrence Barsalou]], [[Michael Turvey]], [[Vittorio Guidano]] and [[Eleanor Rosch]]
* From the perspective of linguistics, [[Gilles Fauconnier]], [[George Lakoff]], [[Mark Johnson (philosopher)|Mark Johnson]], [[Leonard Talmy]] and [[Mark Turner (cognitive scientist)|Mark Turner]]
* From the perspective of language acquisition, [[Eric Lenneberg]] and [[Philip Rubin]] at [[Haskins Laboratories]]
* From the perspective of anthropology, [[Edwin Hutchins]], [[Bradd Shore]], [[James Wertsch]] and [[Merlin Donald]].
* From the perspective of autonomous agent design, early work is sometimes attributed to [[Rodney Brooks]] or [[Valentino Braitenberg]]
* From the perspective of artificial intelligence, ''Understanding Intelligence'' by [[Rolf Pfeifer]] and Christian Scheier or ''How the Body Shapes the Way We Think'', by Rolf Pfeifer and Josh C. Bongard
* From the perspective of philosophy, [[Andy Clark]], [[Dan Zahavi]], [[Shaun Gallagher]], and [[Evan Thompson]]
In 1950, [[Alan Turing]] proposed that a machine may need a human-like body to think and speak:
{{Quote|It can also be maintained that it is best to provide the machine with the best sense organs that money can buy, and then teach it to understand and speak English. That process could follow the normal teaching of a child. Things would be pointed out and named, etc. Again, I do not know what the right answer is, but I think both approaches should be tried.}}
Step 3: Embed Document Chunks

Once the documents are appropriately chunked, you can use OpenAI to compute the embeddings for each string. In this section, you’ll learn a basic example of generating embeddings — make sure you replace the highlighted line with your own API key.
If you haven’t set up your OpenAI API key, make sure to follow this tutorial:

 Recommended: OpenAI Python API – A Helpful Illustrated Guide in 5 Steps
Recommended: OpenAI Python API – A Helpful Illustrated Guide in 5 Steps
Again you can also copy and paste the full code at the end of this article for ease of use:
import openai
import pandas as pd
# Constants for calculating embeddings
EMBEDDING_MODEL = "text-embedding-ada-002" # this may change over time
BATCH_SIZE = 1000 # Maximum of 2048 embedding inputs per request allowed
# your openai key
openai.api_key = 'sk-...'
def calculate_embeddings(wikipedia_strings):
"""Calculate embeddings for a list of strings."""
embeddings = []
total_strings = len(wikipedia_strings)
for batch_start in range(0, total_strings, BATCH_SIZE):
batch_end = min(batch_start + BATCH_SIZE, total_strings)
batch = wikipedia_strings[batch_start:batch_end]
print(f"Processing Batch {batch_start} to {batch_end-1}")
# Requesting embeddings from OpenAI API
response = openai.Embedding.create(model=EMBEDDING_MODEL, input=batch)
# Verifying the order of embeddings
for i, be in enumerate(response["data"]):
assert i == be["index"], "Mismatch in embedding order"
# Extracting and storing embeddings
batch_embeddings = [e["embedding"] for e in response["data"]]
embeddings.extend(batch_embeddings)
return embeddings
# Calculate embeddings for Wikipedia strings
embeddings = calculate_embeddings(wikipedia_strings)
# Creating a DataFrame to store text and corresponding embeddings
df = pd.DataFrame({"text": wikipedia_strings, "embedding": embeddings})
Explanation:
This Python script is used to compute embeddings for a collection of text from Wikipedia. It uses the OpenAI API, specifically the "text-embedding-ada-002" model, to generate embeddings for each text in batches of 1000.
The calculate_embeddings function processes each batch of text, sends it to the OpenAI API, and collects the embeddings returned. It ensures the order of embeddings matches the input text.
After processing all batches, the text and their corresponding embeddings are stored together in a pandas DataFrame. The OpenAI API key is required for accessing the API, and it’s set at the beginning of the script.
In my case, the output is simple:
Processing Batch 0 to 999 Processing Batch 1000 to 1419
Step 4: Store Document Chunks and Embeddings
Finally, you want to store the generated embeddings for future use. Depending on the scale of your data, you can opt for different storage solutions. In the case of smaller datasets, you can store the sections and their respective embeddings in a CSV file. Pandas provides an easy-to-use method for achieving this:
df = pd.DataFrame({"text": wikipedia_strings, "embedding": embeddings})
df.to_csv("artificial_intelligence_wiki.csv", index=False)
Here’s how the CSV file looks like in my AI example — it has 49MB of data, i.e., almost all Wikipedia pages in the category AI!
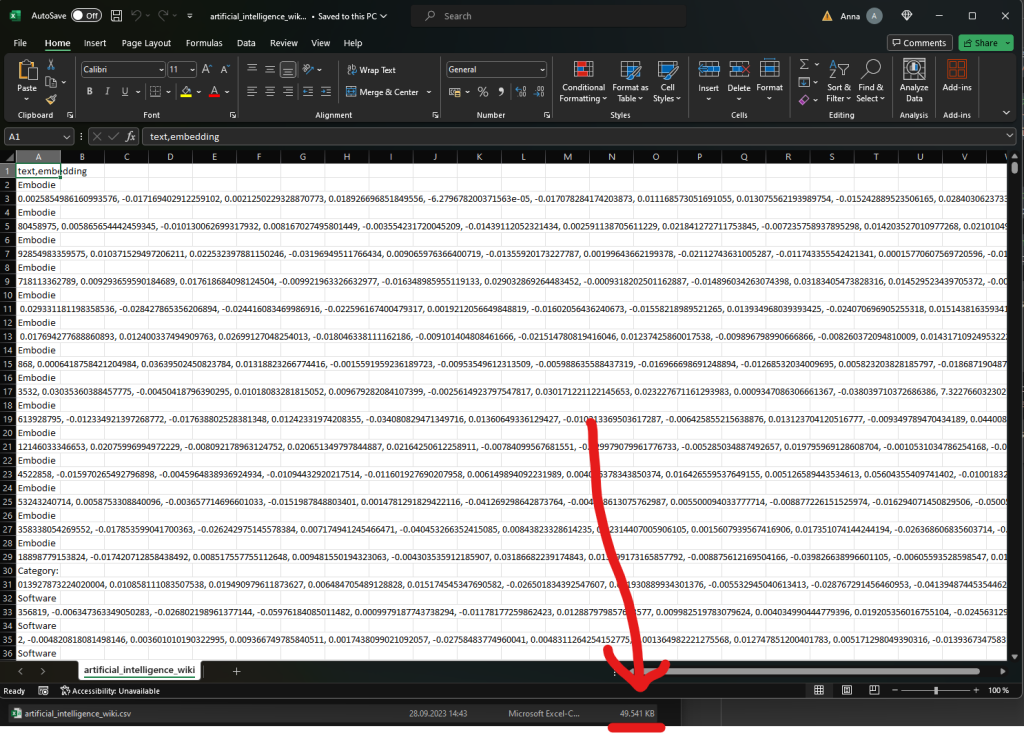
The path to the CSV file will depend on your directory structure.
By following this step-by-step guide, you can proficiently prepare a dataset of Wikipedia articles embedded for search, utilizing the OpenAI library.  This will help in facilitating extensive research or information extraction in various projects.
This will help in facilitating extensive research or information extraction in various projects.
In particular, you can use the embeddings for search or Q&A on a vast text corpus as shown in this GitHub:
Recommended: Question answering using embeddings-based search
If you want to learn the ins and outs of OpenAI Function Calls and Embeddings, check out our academy courses (all-you-can-learn):
Prompt Engineering with Python and OpenAI
You can check out the whole course on OpenAI Prompt Engineering using Python on the Finxter academy. We cover topics such as:
- Embeddings
- Semantic search
- Web scraping
- Query embeddings
- Movie recommendation
- Sentiment analysis
 Academy: Prompt Engineering with Python and OpenAI
Academy: Prompt Engineering with Python and OpenAI
As promised multiple times throughout the article, here’s the whole code for copy and paste:
import mwclient
import regex as re
import mwparserfromhell
import tiktoken
import openai
import pandas as pd
WIKI_SITE = 'en.wikipedia.org'
GPT_MODEL = "gpt-3.5-turbo" # which tokenizer to use?
# Constants for calculating embeddings
EMBEDDING_MODEL = "text-embedding-ada-002" # this may change over time
BATCH_SIZE = 1000 # Maximum of 2048 embedding inputs per request allowed
CATEGORY_TITLE = "Category:Artificial intelligence"
WIKI_SITE = "en.wikipedia.org"
# your openai key
openai.api_key = 'sk-...'
SECTIONS_TO_IGNORE = set([
"See also", "References", "External links", "Further reading", "Footnotes",
"Bibliography", "Sources", "Citations", "Literature", "Notes and references",
"Photo gallery", "Works cited", "Photos", "Gallery", "Notes",
"References and sources", "References and notes",
])
def titles_from_category(category: mwclient.listing.Category, max_depth: int) -> set[str]:
"""
Return a set of page titles in a given Wiki category and its subcategories.
:param category: The Wiki category to retrieve titles from.
:param max_depth: The maximum depth to search for subcategories.
:return: A set of page titles.
"""
titles = set()
for member in category.members():
if isinstance(member, mwclient.page.Page):
titles.add(member.name)
elif isinstance(member, mwclient.listing.Category) and max_depth > 0:
titles.update(titles_from_category(member, max_depth=max_depth - 1))
return titles
def all_subsections_from_section(section, parent_titles, sections_to_ignore):
headings = [str(h) for h in section.filter_headings()]
title = headings[0].strip("= ").strip()
if title in sections_to_ignore:
return []
titles = parent_titles + [title]
section_text = str(section).split(title, 1)[1]
if len(headings) == 1:
return [(titles, section_text)]
first_subtitle = headings[1]
section_text = section_text.split(first_subtitle, 1)[0]
results = [(titles, section_text)]
for subsection in section.get_sections(levels=[len(titles) + 1]):
results.extend(all_subsections_from_section(subsection, titles, sections_to_ignore))
return results
def all_subsections_from_title(title, sections_to_ignore=SECTIONS_TO_IGNORE, site_name=WIKI_SITE):
site = mwclient.Site(site_name)
page = site.pages[title]
parsed_text = mwparserfromhell.parse(page.text())
headings = [str(h) for h in parsed_text.filter_headings()]
summary_text = str(parsed_text).split(headings[0], 1)[0] if headings else str(parsed_text)
results = [([title], summary_text)]
for subsection in parsed_text.get_sections(levels=[2]):
results.extend(all_subsections_from_section(subsection, [title], sections_to_ignore))
return results
def clean_section(section):
titles, text = section
text = re.sub(r"<ref.*?</ref>", "", text).strip()
return titles, text
def keep_section(section):
_, text = section
return len(text) >= 16
def process_titles(titles):
wikipedia_sections = []
for title in titles:
wikipedia_sections.extend(all_subsections_from_title(title))
wikipedia_sections = [clean_section(ws) for ws in wikipedia_sections]
original_num_sections = len(wikipedia_sections)
wikipedia_sections = [ws for ws in wikipedia_sections if keep_section(ws)]
print(f"Filtered out {original_num_sections - len(wikipedia_sections)} sections, leaving {len(wikipedia_sections)} sections.")
return wikipedia_sections
def num_tokens(text: str, model: str = GPT_MODEL) -> int:
"""Return the number of tokens in a string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def halved_by_delimiter(string: str, delimiter: str = "\n") -> list[str, str]:
"""Split a string in two, on a delimiter, trying to balance tokens on each side."""
chunks = string.split(delimiter)
if len(chunks) == 1:
return [string, ""] # no delimiter found
elif len(chunks) == 2:
return chunks # no need to search for halfway point
else:
total_tokens = num_tokens(string)
halfway = total_tokens // 2
best_diff = halfway
for i, chunk in enumerate(chunks):
left = delimiter.join(chunks[: i + 1])
left_tokens = num_tokens(left)
diff = abs(halfway - left_tokens)
if diff >= best_diff:
break
else:
best_diff = diff
left = delimiter.join(chunks[:i])
right = delimiter.join(chunks[i:])
return [left, right]
def truncated_string(
string: str,
model: str,
max_tokens: int,
print_warning: bool = True,
) -> str:
"""Truncate a string to a maximum number of tokens."""
encoding = tiktoken.encoding_for_model(model)
encoded_string = encoding.encode(string)
truncated_string = encoding.decode(encoded_string[:max_tokens])
if print_warning and len(encoded_string) > max_tokens:
print(f"Warning: Truncated string from {len(encoded_string)} tokens to {max_tokens} tokens.")
return truncated_string
def split_strings_from_subsection(
subsection: tuple[list[str], str],
max_tokens: int = 1000,
model: str = GPT_MODEL,
max_recursion: int = 5,
) -> list[str]:
"""
Split a subsection into a list of subsections, each with no more than max_tokens.
Each subsection is a tuple of parent titles [H1, H2, ...] and text (str).
"""
titles, text = subsection
string = "\n\n".join(titles + [text])
num_tokens_in_string = num_tokens(string)
# if length is fine, return string
if num_tokens_in_string <= max_tokens:
return [string]
# if recursion hasn't found a split after X iterations, just truncate
elif max_recursion == 0:
return [truncated_string(string, model=model, max_tokens=max_tokens)]
# otherwise, split in half and recurse
else:
titles, text = subsection
for delimiter in ["\n\n", "\n", ". "]:
left, right = halved_by_delimiter(text, delimiter=delimiter)
if left == "" or right == "":
# if either half is empty, retry with a more fine-grained delimiter
continue
else:
# recurse on each half
results = []
for half in [left, right]:
half_subsection = (titles, half)
half_strings = split_strings_from_subsection(
half_subsection,
max_tokens=max_tokens,
model=model,
max_recursion=max_recursion - 1,
)
results.extend(half_strings)
return results
# otherwise no split was found, so just truncate (should be very rare)
return [truncated_string(string, model=model, max_tokens=max_tokens)]
def calculate_embeddings(wikipedia_strings):
"""Calculate embeddings for a list of strings."""
embeddings = []
total_strings = len(wikipedia_strings)
for batch_start in range(0, total_strings, BATCH_SIZE):
batch_end = min(batch_start + BATCH_SIZE, total_strings)
batch = wikipedia_strings[batch_start:batch_end]
print(f"Processing Batch {batch_start} to {batch_end-1}")
# Requesting embeddings from OpenAI API
response = openai.Embedding.create(model=EMBEDDING_MODEL, input=batch)
# Verifying the order of embeddings
for i, be in enumerate(response["data"]):
assert i == be["index"], "Mismatch in embedding order"
# Extracting and storing embeddings
batch_embeddings = [e["embedding"] for e in response["data"]]
embeddings.extend(batch_embeddings)
return embeddings
site = mwclient.Site(WIKI_SITE)
category_page = site.pages[CATEGORY_TITLE]
titles = titles_from_category(category_page, max_depth=1)
wikipedia_sections = process_titles(titles)
# split sections into chunks
MAX_TOKENS = 1600
wikipedia_strings = []
for section in wikipedia_sections:
wikipedia_strings.extend(split_strings_from_subsection(section, max_tokens=MAX_TOKENS))
print(f"{len(wikipedia_sections)} Wikipedia sections split into {len(wikipedia_strings)} strings.")
# print example data
print(wikipedia_strings[1])
# Calculate embeddings for Wikipedia strings
embeddings = calculate_embeddings(wikipedia_strings)
# Creating a DataFrame to store text and corresponding embeddings
df = pd.DataFrame({"text": wikipedia_strings, "embedding": embeddings})
df.to_csv("data/artificial_intelligence_wiki.csv", index=False)
The post How to Create a Massive OpenAI Embeddings CSV File for Search – From 100s of Wikipedia Articles appeared first on Be on the Right Side of Change.
Find A Teacher Form:
https://docs.google.com/forms/d/1vREBnX5n262umf4wU5U2pyTwvk9O-JrAgblA-wH9GFQ/viewform?edit_requested=true#responses
Email:
public1989two@gmail.com
www.itsec.hk
www.itsec.vip
www.itseceu.uk
Leave a Reply