When working with lists that contain Unicode strings, you may encounter characters that make it difficult to process or manipulate the data or handle internationalized content or content with emojis  . In this article, we will explore the best ways to remove Unicode characters from a list using Python.
. In this article, we will explore the best ways to remove Unicode characters from a list using Python.
You’ll learn several strategies for handling Unicode characters in your lists, ranging from simple encoding techniques to more advanced methods using list comprehensions and regular expressions.
Understanding Unicode and Lists in Python
Combining Unicode strings and lists in Python is common when handling different data types. You might encounter situations where you need to remove Unicode characters from a list, for instance, when cleaning or normalizing textual data.
Unicode is a universal character encoding standard that represents text in almost every writing system used today. It assigns a unique identifier to each character, enabling the seamless exchange and manipulation of text across various platforms and languages. In Python 2, Unicode strings are represented with the u prefix, like u'Hello, World!'. However, in Python 3, all strings are Unicode by default, making the u prefix unnecessary.
 Lists are a built-in Python data structure used to store and manipulate collections of items. They are mutable, ordered, and can contain elements of different types, including Unicode strings.
Lists are a built-in Python data structure used to store and manipulate collections of items. They are mutable, ordered, and can contain elements of different types, including Unicode strings.
For example:
my_list = ['Hello', u'世界', 42]
While working with Unicode and lists in Python, you may discover challenges related to encoding and decoding strings, especially when transitioning between Python 2 and Python 3. Several methods can help you overcome these challenges, such as encode(), decode(), and using various libraries.
Method 1: ord() for Unicode Character Identification
One common method to identify Unicode characters is by using the isalnum() function. This built-in Python function checks if all characters in a string are alphanumeric (letters and numbers) and returns True if that’s the case, otherwise False. When working with a list, you can simply iterate through each string item and use isalnum() to determine if any Unicode characters are present.
The isalnum() function in Python checks whether all the characters in a text are alphanumeric (i.e., either letters or numbers) and does not specifically identify Unicode characters. Unicode characters can also be alphanumeric, so isalnum() would return True for many Unicode characters.
To identify or work with Unicode characters in Python, you might use the ord() function to get the Unicode code of a character, or \u followed by the Unicode code to represent a character. Here’s a brief example:
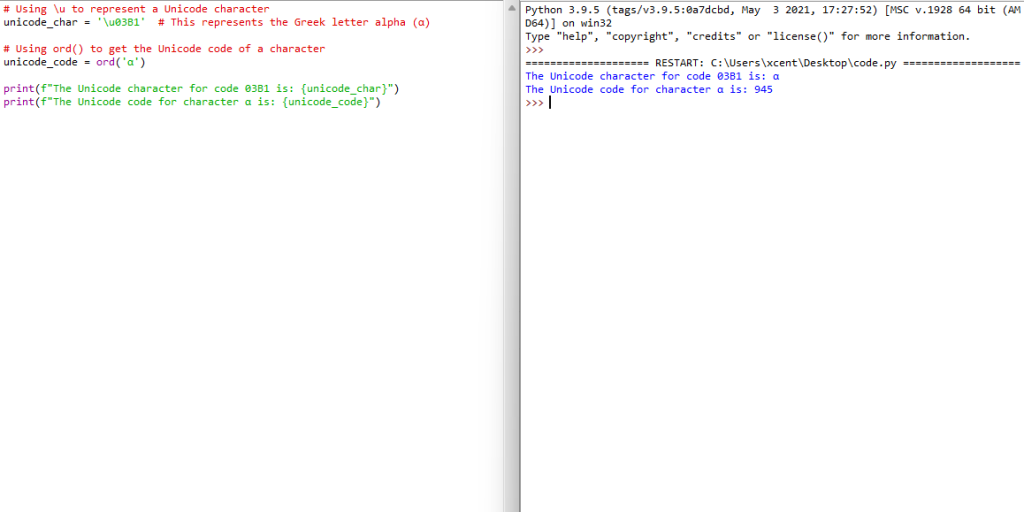
# Using \u to represent a Unicode character
unicode_char = '\u03B1' # This represents the Greek letter alpha (α)
# Using ord() to get the Unicode code of a character
unicode_code = ord('α')
print(f"The Unicode character for code 03B1 is: {unicode_char}")
print(f"The Unicode code for character α is: {unicode_code}")
In this example:
\u03B1is used to represent the Greek letter alpha (α) using its Unicode code.ord('α')returns the Unicode code for the Greek letter alpha, which is945.
If you want to identify whether a string contains non-ASCII characters (which might be what you’re interested in when you talk about identifying Unicode characters), you might use something like the following code:
def contains_non_ascii(s):
return any(ord(char) >= 128 for char in s)
# Example usage:
s = "Hello α"
print(contains_non_ascii(s)) # Output: True
print(contains_non_ascii('Hello World')) # Output: False
In this function, contains_non_ascii(s), it checks each character in the string s to see if it has a Unicode code greater than or equal to 128 (i.e., it is not an ASCII character). If any such character is found, it returns True; otherwise, it returns False.
Method 2: Regex for Unicode Identification
Using regular expressions (regex) is a powerful way to identify Unicode characters in a string. Python’s re module can be utilized to create patterns that can match Unicode characters. Below is an example method that uses a regular expression to identify whether a string contains any Unicode characters:
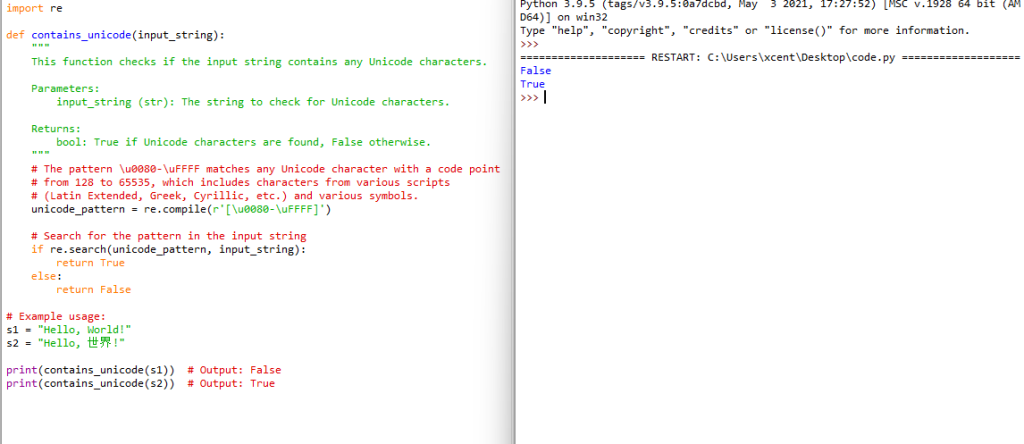
import re
def contains_unicode(input_string):
"""
This function checks if the input string contains any Unicode characters.
Parameters:
input_string (str): The string to check for Unicode characters.
Returns:
bool: True if Unicode characters are found, False otherwise.
"""
# The pattern \u0080-\uFFFF matches any Unicode character with a code point
# from 128 to 65535, which includes characters from various scripts
# (Latin Extended, Greek, Cyrillic, etc.) and various symbols.
unicode_pattern = re.compile(r'[\u0080-\uFFFF]')
# Search for the pattern in the input string
if re.search(unicode_pattern, input_string):
return True
else:
return False
# Example usage:
s1 = "Hello, World!"
s2 = "Hello, 世界!"
print(contains_unicode(s1)) # Output: False
print(contains_unicode(s2)) # Output: True
Explanation:
[\u0080-\uFFFF]: This pattern matches any character with a Unicode code point fromU+0080toU+FFFF, which includes various non-ASCII characters.re.search(unicode_pattern, input_string): This function searches the input string for the defined Unicode pattern.- If the pattern is found in the string, the function returns
True; otherwise, it returnsFalse.
This method will help you identify strings containing Unicode characters from various scripts and symbols. This pattern does not match ASCII characters (code points U+0000 to U+007F) or non-BMP characters (code points above U+FFFF).
If you want to learn about Python’s search() function in regular expressions, check out my tutorial and tutorial video:

Method 3: Encoding and Decoding for Unicode Removal
When dealing with Python lists containing Unicode characters, you might find it necessary to remove them. One effective method to achieve this is by using the built-in string encoding and decoding functions. This section will guide you through the process of Unicode removal in lists by employing the encode() and decode() methods.
First, you will need to encode the Unicode string into the ASCII format. It is essential because the ASCII encoding only supports ASCII characters, and any Unicode characters that are outside the ASCII range will be automatically removed. For this, you can utilize the encode() function with its parameters set to the ASCII encoding option and error handling set to 'ignore'.
For example:
string_unicode = "? ?? ???????!"
string_ascii = string_unicode.encode('ascii', 'ignore')
After encoding the string to ASCII, it is time to decode it back to a UTF-8 format. This step is essential to ensure the list items retain their original text data and stay readable. You can use the decode() function to achieve this conversion. Here’s an example:
string_utf8 = string_ascii.decode('utf-8')
Now that you have successfully removed the Unicode characters, your Python list will only contain ASCII characters, making it easier to process further. Let’s take a look at a practical example with a list of strings.
list_unicode = ["? ?? ???????!", "This is an ASCII string", "???? ?? ???????"]
list_ascii = [item.encode('ascii', 'ignore').decode('utf-8') for item in list_unicode]
print(list_unicode)
# ['? ?? ???????!', 'This is an ASCII string', '???? ?? ???????']
print(list_ascii)
# [' !', 'This is an ASCII string', ' ']
In this example, the list_unicode variable comprises three different strings, two with Unicode characters and one with only ASCII characters. By employing a list comprehension, you can apply the encoding and decoding process to each string in the list.
 Recommended: Python List Comprehension – The Ultimate Guide
Recommended: Python List Comprehension – The Ultimate Guide
Remember always to be careful when working with Unicode texts. If the string with Unicode characters contains crucial information or an essential part of the data you are processing, you should consider keeping the Unicode characters and using proper Unicode-compatible solutions.
Method 4: The Replace Function for Unicode Removal
When working with lists in Python, it is common to come across Unicode characters that need to be removed or replaced. One technique to achieve this is by using Python’s replace() function.
The replace() function is a built-in method in Python strings, which allows you to replace occurrences of a substring within a given string. To remove specific Unicode characters from a list, you can first convert the list elements into strings, then use the replace() function to handle the specific Unicode characters.
Here’s a simple example:
original_list = ["Róisín", "Björk", "Héctor"]
new_list = []
for item in original_list:
new_item = item.replace("ó", "o").replace("ö", "o").replace("é", "e")
new_list.append(new_item)
print(new_list) # ['Roisin', 'Bjork', 'Hector']
When dealing with a larger set of Unicode characters, you can use a dictionary to map each character to be replaced with its replacement. For example:
unicode_replacements = {
"ó": "o",
"ö": "o",
"é": "e",
# Add more replacements as needed.
}
original_list = ["Róisín", "Björk", "Héctor"]
new_list = []
for item in original_list:
for key, value in unicode_replacements.items():
item = item.replace(key, value)
new_list.append(item)
print(new_list) # ['Roisin', 'Bjork', 'Hector']
Of course, this is only useful if you have specific Unicode characters to remove. Otherwise, use the previous Method 3.
Method 5: Regex Substituion for Replacing Non-ASCII Characters
When working with text data in Python, non-ASCII characters can often cause issues, especially when parsing or processing data. To maintain a clean and uniform text format, you might need to deal with these characters and remove or replace them as necessary.
One common technique is to use list comprehension coupled with a character encoding method such as .encode('ascii', 'ignore'). You can loop through the items in your list, encode them to ASCII, and ignore any non-ASCII characters during the encoding process. Here’s a simple example:
data_list = ["? ?? ???????!", "Hello, World!", "你好!"]
clean_data_list = [item.encode("ascii", "ignore").decode("ascii") for item in data_list]
print(clean_data_list)
# Output: [' m mn!', 'Hello, World!', '']
In this example, you’ll notice that non-ASCII characters are removed from the text, leaving the ASCII characters intact. This method is both clear and easy to implement, which makes it a reliable choice for most situations.
Another approach is to use regular expressions to search for and remove all non-ASCII characters. The Python re module provides powerful pattern matching capabilities, making it an excellent tool for this purpose. Here’s an example that shows how you can use the re module to remove non-ASCII characters from a list:
import re data_list = ["? ?? ???????!", "Hello, World!", "你好!"] ascii_only_pattern = re.compile(r"[^\x00-\x7F]") clean_data_list = [re.sub(ascii_only_pattern, "", item) for item in data_list] print(clean_data_list) # Output: [' !', 'Hello, World!', '']
In this example, we define a regular expression pattern that matches any character outside the ASCII range ([^\x00-\x7F]). We then use the re.sub() function to replace any matching characters with an empty string.
Frequently Asked Questions
How can I efficiently replace Unicode characters with ASCII in Python?
To efficiently replace Unicode characters with ASCII in Python, you can use the unicodedata library. This library provides the normalize() function which can convert Unicode strings to their closest ASCII equivalent. For example:
import unicodedata
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn')
This function will replace Unicode characters with their ASCII equivalents, making your Python list easier to work with.
What are the best methods to remove Unicode characters in Pandas?
Pandas has a built-in method that helps you remove Unicode characters in a DataFrame. You can use the applymap() function in conjunction with the lambda function to remove any non-ASCII character from your DataFrame. For example:
import pandas as pd
data = {'col1': [u'こんにちは', 'Pandas', 'DataFrames']}
df = pd.DataFrame(data)
df = df.applymap(lambda x: x.encode('ascii', 'ignore').decode('ascii'))
This will remove all non-ASCII characters from the DataFrame, making it easier to process and analyze.
How do I get rid of all non-English characters in a Python list?
To remove all non-English characters in a Python list, you can use list comprehension and the isalnum() function from the str class. For example:
data = [u'こんにちは', u'Hello', u'안녕하세요'] result = [''.join(c for c in s if c.isalnum() and ord(c) < 128) for s in data]
This approach filters out any character that isn’t alphanumeric or has an ASCII value greater than 127.
What is the most effective way to eliminate Unicode characters from an SQL string?
To eliminate Unicode characters from an SQL string, you should first clean the data in your programming language (e.g., Python) before inserting it into the SQL database. In Python, you can use the re library to remove Unicode characters:
import re
def clean_sql_string(s):
return re.sub(r'[^\x00-\x7F]+', '', s)
This function will remove any non-ASCII characters from the string, ensuring that your SQL query is free of Unicode characters.
How can I detect and handle Unicode characters in a Python script?
To detect and handle Unicode characters in a Python script, you can use the ord() function to check if a character’s Unicode code point is outside the ASCII range. This allows you to filter out any Unicode characters in a string. For example:
def is_ascii(s):
return all(ord(c) < 128 for c in s)
You can then handle the detected Unicode characters accordingly, such as using replace() to substitute them with appropriate ASCII characters or removing them entirely.
What techniques can be employed to remove non-UTF-8 characters from a text file using Python?
To remove non-UTF-8 characters from a text file using Python, you can use the following method:
- Open the file in binary mode.
- Decode the file’s content with the ‘UTF-8’ encoding, using the ‘ignore’ or ‘replace’ error handling mode.
- Write the decoded content back to the file.
with open('file.txt', 'rb') as file:
content = file.read()
cleaned_content = content.decode('utf-8', 'ignore')
with open('cleaned_file.txt', 'w', encoding='utf-8') as file:
file.write(cleaned_content)
This will create a new text file without non-UTF-8 characters, making your data more accessible and usable.
Footnotes
- 7 Best Ways to Remove Unicode Characters in Python
- What is the simplest way to remove unicode ‘u’ from a list
The post Best Ways to Remove Unicode from List in Python appeared first on Be on the Right Side of Change.
Find A Teacher Form:
https://docs.google.com/forms/d/1vREBnX5n262umf4wU5U2pyTwvk9O-JrAgblA-wH9GFQ/viewform?edit_requested=true#responses
Email:
public1989two@gmail.com
www.itsec.hk
www.itsec.vip
www.itseceu.uk
Leave a Reply